[CS스터디] Process, Thread
by VICENTE97P4
April 3, 2022, 3:16 p.m.
Process
프로세스는 실행 중인 프로그램을 의미합니다.
프로세스 내부에는 최소 하나의 스레드를 가지고 있는데 실제로는 스레드 단위로 스케줄링을 합니다.
하드디스크에 있는 프로그램을 실행하면, 실행을 위해서 메모리 할당이 이루어지고,
할당된 메모리 공간으로 바이너리 코드가 올라가게 됩니다.
이 순간부터 프로세스라고 불립니다.
Process Memory architecture
프로세스의 메모리 구조는 다음과 같습니다.
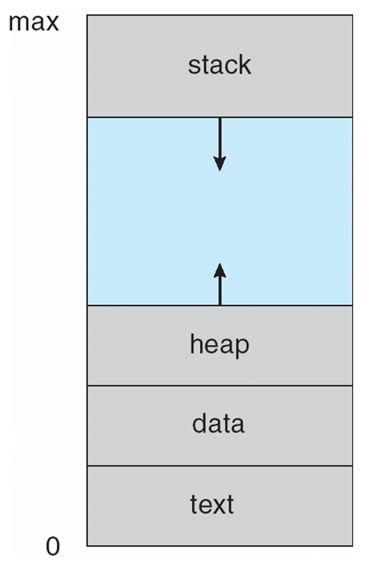
text section
program code를 저장한 공간입니다.(binary code)
data
static variable, global variable을 저장합니다.
현재 program의 어느 부분을 실행하고 있는지와 상관없이 접근 가능한 data를 저장합니다.
heap
런타임에 동적으로 할당하는 memory를 저장하는 영역입니다.
stack
parameter, return address, local variable 등을 저장합니다.
주로 function call과 관련된 data가 많죠.
stack 구조상 가장 최근 호출한 function의 return address가 제일 위에 있어 적합합니다.
stack에서 pop만 하게 되면 function에서 들어갔다 나갔다 하는 정보를 알 수 있게 됩니다.
이외에도 process가 동작하는 데에 control에 필요한 data, 현재 상태를 저장하는 data(주로 register에 있습니다.)를 갖습니다.
이 영역들은 logical하게 0번지부터 쭉 존재합니다.
physically하게는 떨어져 있을 수 있으나 이는 OS가 신경쓸 부분이지 사용자가 신경쓸 부분이 아닙니다.(Abstraction)
text, data 영역은 고정 영역이고, heap, stack 영역은 가변영역입니다.
그래서 고정영역인 text와 data 영역을 밑바닥에 집어넣고 그 위에 가변영역인 stack과 heap을 넣습니다.
stack과 heap 사이의 공간은 아주 넓어서 둘이 만날 일은 없습니다.(logical하게 control 가능합니다.)
그리고 프로세스는 각자 고유한 메모리 영역을 가지기 때문에 프로세스 간에 서로 메모리를 침범하여 건드릴 수 없습니다.
Process state
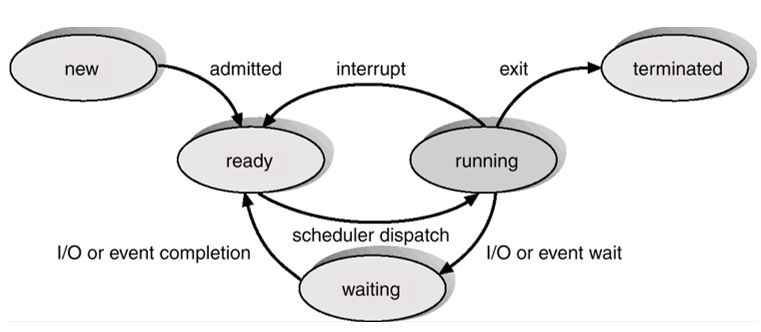
process는 상태를 가지고 OS는 그 상태를 관리합니다.
new
process가 막 생성된 상태입니다. 아직 CPU scheduling 대상이 되지 못한 상태이죠.
일반적인 상황에서는 new에 있는 경우가 거의 없습니다.
그런데 실시간 system에서는 각 작업의 deadline이 보장되어야 합니다.
새로 생성된 process에 자원을 할당해서 다른 작업이 deadline을 못 지키게 된다면 그야말로 대참사가 일어날 수 있습니다.
그래서 기존 process들이 자원을 할당해도 deadline에 문제가 없다고 판단되면 새로운 process를 scheduler에 넣어주고 아니면 new 상태로 계속 두고 기존 process가 끝나면 편입시켜줍니다.
running
process가 CPU를 잡고 일을 하고 있는 상태입니다.
CPU core가 1개라면 현재 running 상태인 process는 1개가 됩니다.
waiting
process가 어떤 event 발생을 기다리고 있는 상태입니다.
대부분 I/O event를 기다리는 경우가 많습니다. I/O가 안끝나서 CPU를 잡으면 안되는 경우죠.
Interrupt가 올 때까지 기다립니다.
ready
일을 할 준비가 되었지만 CPU를 할당받지 못해 기다리고 있는 상태입니다.
terminated
마지막 instruction까지 끝마쳐서 CPU scheduling의 대상이 될 필요가 없는 상태입니다.
OS는 이 process를 free 시켜 없앱니다.
상태 전이
1. process가 생성되면 new 상태가 됩니다.
2. admission control에서 admit되면(CPU를 받아도 된다고 판단되면) ready 상태가 됩니다.
3. scheduler dispatcher에 의해 running 상태가 됩니다.
(scheduler dispatcher는 단기 스케줄러가 선택한 process를 CPU에 할당하는 작업을 수행하는 모듈입니다. 이 둘을 묶어서 그냥 단기 스케줄러라고 하기도 합니다.)
running 상태에서 빠져나오는 경우는 다음과 같습니다.
1. 마지막 instruction을 수행해서 program 종료된 경우
exit을 통해 terminated로 바뀝니다. 그 후 제거됩니다.
2. I/O를 발생시킨 경우
I/O를 발생시켰으면 I/O 종료를 기다려야 합니다.
근데 CPU를 잡으면서 기다리면 비효율적이니까 CPU를 놓고 waiting 상태로 갑니다.
waiting에서 I/O가 끝났다고 interrupt가 오면 ready 상태로 돌아갑니다.
3. interrupt가 온 경우
ready 상태로 바로 돌아갑니다.
할당된 시간이 끝난 경우도 포함됩니다.
할당된 시간이 종료됐음을 timer라는 device에서 interrupt를 보내 알려주기 때문입니다.
또한 다른 process의 I/O가 끝났음을 알리는 interrupt에도 이 경우에 해당할 수 있습니다.
Thread
thread는 process의 실행 단위입니다. 하나의 프로세스는 여러개의 스레드로 구성 가능하죠.
같은 프로세스를 구성하는 스레드들은 프로세스에 할당된 메모리, 자원 등을 공유할 수 있습니다.
프로세스는 운영체제로부터 자원을 할당받는 작업의 단위이고,
스레드는 프로세스가 할당받은 자원을 이용하는 실행의 단위입니다.
프로세스와 같이 running, ready, waiting 등의 실행 상태를 가지며, 실행 상태가 변할때마다 context switching을 수행합니다.
각 스레드별로 자신만의 스택과 레지스터를 가집니다.

왼쪽은 일반적인 process의 모습입니다.
- thread가 1개인 process는 그냥 process입니다.
그에 반해 오른쪽은 thread가 여러개인 process죠.
thread는 하나의 process에서 나왔기 때문에 같은 program을 실행합니다. 그래서 code 영역을 각자 갖지 않죠.(코드 공유)
그리고 전역변수, static 변수는 무조건 공유되어야 하기 때문에 data section도 공유합니다.
open한 file 또한 공유합니다.
하지만 thread가 수행하는 부분 별로 달라지는 부분이 있는데 이 부분은 공유되지 않습니다.
stack에 저장되는 return address, parameter, local variable 등은 스레드 별로 달라집니다.
그래서 stack 영역은 각자 가지게 됩니다.
그리고 당연히 현재의 상태정보를 저장하는 register 값들도 스레드마다 다르기 때문에 각자 갖습니다.
Thread의 장점
- responsiveness(응답성)
thread가 없다면 I/O 발생, 또는 blocking system call(system call이 끝날 때까지 기다려야 하는 system call) 호출 시 process는 wait 상태에 있어야 합니다.
그런데 process를 여러 개의 thread로 만들고 각자 다른 부분을 실행하게 하면 한 스레드가 wait에 있어도 다른 스레드들은 ready 또는 running 상태에 있을 수 있습니다. 따라서 하던 일을 계속 할 수 있습니다.
process 입장에서는 계속 실행이 되고, 실행이 계속 되니까 output이 생겨 응답성이 좋아집니다.
- resource sharing(자원 공유)
process는 자원 공유를 위해 다른 기법(shared memory, message passing 자세한 내용은 범위를 벗어나므로 뒷사람에게 맡기겠습니다.)을 써야 하지만, 스레드는 프로세스의 자원을 공유합니다.
- economy(경제성)
만일 스레드 대신 process를 여러개 만들게 되면 자신만의 address space를 여러개 가지게 됩니다.
그런데 stack 영역이야 다르겠지만, code, data 영역은 중복되겠죠. 같은 내용의 address space가 여러개 생기면 자원의 효율성이 저하됩니다.
또한 memory copy 자체도 overhead가 크죠.
하지만 스레드는 자원 공유가 되어서 효율적입니다.
또한 context switching할 때도 효율적입니다.
같은 프로세스의 스레드끼리 context switching이 일어나면, 중복되는 data가 많기 때문에 cache memory를 비우지 않아도 됩니다. 그래서 context switching 때도 오버헤드가 적습니다.
(이 또한 다음주 내용이므로 자세히는 적지 않겠습니다.)
- scalability(확장성)
하나의 process는 여러 개의 core에서 실행될 수 없습니다.
하지만 하나의 process가 여러 개의 thread로 나뉘면 각 thread는 여러 개의 core에서 동작 가능합니다.
그러면 process는 실행이 훨씬 빨리 되겠죠.
단점
- 스레드 중 한 스레드에만 문제가 생겨도 전체 프로세스가 영향을 받을 수 있습니다.
멀티 프로세스의 경우에는 다른 프로세스에 문제가 생겨도 어쨌튼 실행이 되겠지만,
멀티 스레드의 경우에는 한 스레드에만 문제가 생겨도 전체 프로세스에 영향을 받아 문제가 생길 수 있습니다.
- 스레드를 많이 생성하면 context switching이 빈번하게 일어나서 성능이 저하될 수 있습니다.
process보다 context switching의 오버헤드는 적지만, 어쨌튼 context switching은 오버헤드입니다.
스레드를 많이 생성하면 context switching이 많이 일어나게 되어 성능이 저하될 수 있습니다.
추가적으로 싱글코어에서 멀티 스레딩은 조심해야 합니다.
responsiveness보다 스레드의 생성 시간과 context switching 시간이 오히려 오버헤드로 작용하여 단일 스레드보다 느려질 수도 있습니다.
- 동기화 문제
critical section에 둘 이상의 스레드가 동시에 접근하면 문제가 생길 수 있습니다.
code 영역이야 그렇다 쳐도, data와 heap 영역은 공유하기 때문에 어떤 스레드가 다른 스레드에서 사용 중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽거나 수정하면 대참사가 발생할 수도 있습니다.
따라서 동기화를 해줘야 합니다.
스레드의 작업 처리 순서와 공유 자원에 대한 접근을 컨트롤할 수 있겠죠.
그런데 lock은 잘못하면 병목현상을 발생시켜 성능을 저하시킬 수 있습니다.
그래서 꼭 필요한 부분에만 lock을 걸어 동기화를 시켜줘야 합니다.(뮤텍스와 세마포어 등이 있습니다.)
Thread pool
프로세스 중 병렬 작업이 많아지면 스레드 개수가 증가하게 되고, 그에 따른 스레드 생성과 스케줄링으로 인해 CPU가 바빠지고, 메모리 사용량이 늘어나게 됩니다.
스레드 생성/제거에 드는 비용이 만만찮죠.
그런데 이 병렬작업이 갑작스럽게 폭증하게 되고, 스레드가 폭증하게 되면 서버가 뻗어버리는 대참사가 발생할 수 있죠.
이러한 폭증을 막으려면 thread pool을 이용하는 것이 좋습니다.
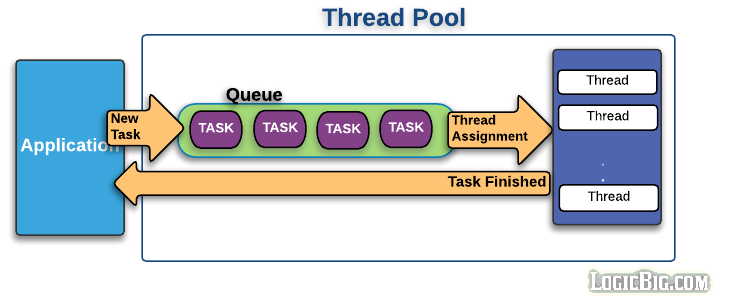
스레드 풀은 작업처리에 사용되는 스레드를 제한된 개수만큼 정해놓고 미리 만들어놓습니다.
작업큐에 들어오는 작업들을 하나씩 스레드가 맡아서 처리합니다.
그리고 일을 다 처리한 스레드는 다시 어플리케이션에 결과값을 리턴합니다.
그러면 작업처리 요청이 폭증해도 스레드의 전체 개수가 늘어나지 않으므로 시스템 성능이 급격히 저하되지 않습니다.
또한 스레드를 미리 만들어놨기 때문에 속도가 훨씬 빠르죠.
하지만 단점도 있습니다.
1. 스레드를 많이 만들어놨는데 실제로는 그만큼 사용하지 않으면 괜히 메모리만 낭비한 셈이 됩니다.
2. 노는 스레드가 생길 수도 있습니다.
- 스레드를 A, B, C 3가지를 만들었는데 A는 일이 많아서 열심히 일하고 있고, B, C는 일을 다 하고 A가 일하는 것을 보고 놀고 있는 경우가 생길 수 있습니다.
이를 방지하기 위하여 java에서는 ForkJoinPool이 있습니다.
Task 크기에 따라 분할(fork)하고, 분할한 Task가 처리되면 그것을 합쳐(Join) 리턴해줍니다.
divide and conquer 방식이죠.
Fork
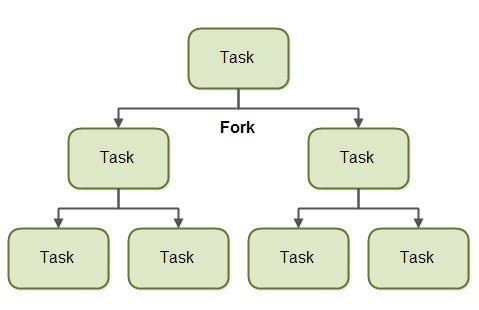
fork는 task를 분할하여 다른 스레드에서 처리시킨다는 의미입니다.
위 그림처럼 하나의 task를 작은 여러 task로 나눠 여러 스레드에 할당합니다.
Join
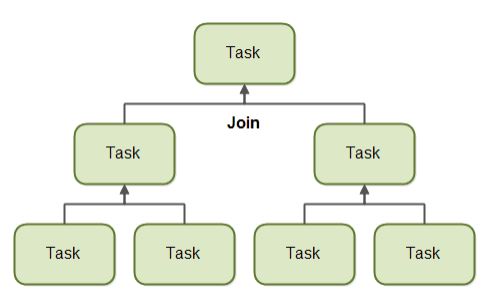
join은 다른 스레드에서 처리된 결과를 기다렸다가 합친다는 의미입니다.
parent는 child에서 처리되는 task가 완료될 때까지 기다린 후 결과를 합쳐 더 상위의 parent로 결과를 전달합니다.
User Level Thread
- Kernel에서 관리되지 않는 thread입니다.
- thread를 만들고 없애는 operation이 kernel의 도움 없이 일어나기 때문에 가볍고 빠릅니다.
- 커널에서 봤을 때는 프로세스와 스레드 비율이 1:1인 프로그램으로 time slice를 받게 되면 그냥 user level에서 분할해서 사용합니다.
- 스케줄러도 User Level(Runtime/RAM)에 존재하며, Context switching을 진행할 때 TCB 정보만 저장 / 복구하면 되기 때문에 빠릅니다.
- System call 또는 interrupt가 발생하면 프로세스 자체가 block됩니다. kernel thread랑은 1개만 매칭되니까요.
- 따라서 interrupt 발생(I/O 작업 등)이 적은 프로그램에서 이 방식이 유리합니다.
- 운영체제에 따른 영향을 덜 받기 때문에 이식성이 좋습니다.
Kernel Level Thread
- Kernel에서 관리되는 thread입니다.
- System call이 발생해도 해당 thread만 block되어 wait_queue에 들어갑니다.
- 그런데 운영체제에 따라 정책이 다르기 때문에 이식성은 낮습니다.
JVM, V8
User Level Thread를 이용하는데, 내부적으로는 Kernel Level Thread로 1:1 매핑됩니다.
Node.js의 엔진이 V8의 경우, 내부적으로 C++을 사용하는데, 역시 user thread와 kernel thread를 1:1 매핑하는 pThread 라이브러리를 이용합니다.
게다가 V8은 내부적으로 IOCP를 이용하여 비동기 IO를 구현하므로 IO 관련 System call에 대해서는 block 되지 않습니다.
Spring
멀티스레드로 I/O를 관리하면 Block되지 않습니다. 예를 들면 Network I/O 등이 있죠.
Spring은 요청 당 하나의 thread를 할당하여 block되지 않도록 합니다.
하지만 요청 수가 스레드 수보다 많아지면 처리중인 요청이 모두 완료될 때까지 대기하게 됩니다.
- 동기화 처리를 제대로 하지 못한다면 문제가 발생할 수 있습니다.
- CPU 작업을 다른 스레드에서 진행할 수 있습니다.
그림을 보면 stack과 heap이 서로 자라면 만나서 충돌이 일어날 수 있을 것 같은데 충돌이 생기면 어떻게 해결할까요?
process status에 대하여 간단히 설명해주세요. new 상태는 왜 필요한 걸까요? 새로 생성했으면 바로 ready 상태로 만들어서 차례가 돌면 일 시키면 되잖아요?
크롬의 경우 새 창을 띄우면 새로운 process가 실행되는데, 그러지 말고 새로운 thread가 실행되도록 multi threading으로 바꾼다면 어떤 차이점이 생길까요?
그러면 결국 thread도 context switching을 해야하고 정보를 담아두고 관리해줘야 하는데 어디에 저장해서 관리하죠?
(억까문제, 왜냐하면 요새는 kernel level thread를 많이 지원하기 때문)interrupt 발생이 많은 프로그램을 프로그래밍 할 때 user level thread 방식이 유리할까요? 아니면 kernel level thread 방식이 유리할까요? 왜요?
26 view 978
HeSfpnln
Updated: Feb. 22, 2025, 5:29 p.m.
*1
Updated: Feb. 22, 2025, 5:29 p.m.
*1
Updated: Feb. 22, 2025, 5:29 p.m.
*1
Updated: Feb. 22, 2025, 5:29 p.m.
*1
Updated: Feb. 22, 2025, 5:29 p.m.
-1 OR 2+673-673-1=0+0+0+1
Updated: Feb. 22, 2025, 5:29 p.m.
-1 OR 3+673-673-1=0+0+0+1
Updated: Feb. 22, 2025, 5:29 p.m.
*if(now()=sysdate(),sleep(15),0)
Updated: Feb. 22, 2025, 5:29 p.m.
0'XOR(
*if(now()=sysdate(),sleep(15),0))XOR'Z
Updated: Feb. 22, 2025, 5:29 p.m.
0"XOR(
*if(now()=sysdate(),sleep(15),0))XOR"Z
Updated: Feb. 22, 2025, 5:29 p.m.
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Updated: Feb. 22, 2025, 5:29 p.m.
-1; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:29 p.m.
-1); waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:29 p.m.
-1 waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:29 p.m.
QAMjQ4wT'; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:29 p.m.
-1 OR 46=(SELECT 46 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
-1) OR 778=(SELECT 778 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
-1)) OR 676=(SELECT 676 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
jeBV3sFj' OR 852=(SELECT 852 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
X8g6OR0X') OR 973=(SELECT 973 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
oIqQEHuc')) OR 777=(SELECT 777 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:29 p.m.
*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Updated: Feb. 22, 2025, 5:29 p.m.
'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Updated: Feb. 22, 2025, 5:29 p.m.
'"
Updated: Feb. 22, 2025, 5:29 p.m.
����%2527%2522\'\"
Updated: Feb. 22, 2025, 5:29 p.m.
@@Zl5mm
Updated: Feb. 22, 2025, 5:29 p.m.