[CS스터디] 트랜잭션
by VICENTE97P4
May 27, 2022, 1:59 p.m.
Transaction
트랜잭션이란 하나의 논리적 작업 단위를 구성하는 일련의 연산들의 집합을 의미합니다.
즉, 하나 이상의 쿼리를 모아 놓은 하나의 작업 단위입니다.
- 각 트랜잭션은 하나의 특정 작업으로 시작해서 모든 작업들을 다 완료해야 정상적으로 종료됩니다.
- 만일 하나의 트랜잭션에 속해있는 여러 작업 중 단 하나의 작업이라도 실패하면, 이 트랜잭션에 속한 모든 작업을 실패한 것으로 판단합니다.
즉, 작업이 하나라도 실패하게 되면 트랜잭션도 실패하고, 모든 작업이 성공적이면 트랜잭션 또한 성공입니다.
ACID
트랜잭션은 ACID라는 특성을 가지고 있습니다.
ACID는 DB 내에서 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질입니다.

- Atomicity(원자성)
- Consistency(일관성)
- Isolation(격리성, 고립성)
- Durability(지속성)
Atomicity(원자성)
한 트랜잭션의 연산들이 모두 성공하거나, 반대로 전부 실패하는 성질을 말합니다.
즉, 작업이 모두 반영되거나 모두 반영되지 않음으로서 결과를 예측할 수 있어야 합니다.
한 연산이라도 실패하면 트랜잭션은 실패해야 합니다.
하나의 단위로 묶여있는 여러 작업이 부분적으로 실행된다면 데이터가 오염될 수 있습니다.
예를 들어 계좌이체를 할 때에는 두 단계가 있다고 합시다.
1. A 계좌에서 출금한다.
2. B 계좌에 입금한다.
그런데 A 계좌에서는 출금이 이루어지고, B 계좌에 입금되지 않았다고 해봅시다.
그런데 어디서 문제가 발생했는지 파악할 수 없다면, A 계좌에서 출금된 돈은 그냥 사라지는 돈이 됩니다.
그럼 은행은 더이상 제 기능을 할 수 없게 되죠.
A 계좌에서 출금하는 일에 성공했지만, B 계좌에 입금하는 작업에 실패한다면 계좌 A에서 출금하는 작업을 포함하여 모든 작업이 실패로 돌아가야 한다는 것이 Atomicity(원자성)입니다.
1, 2번 과정 모두 성공하거나, 하나라도 실패한다면 작업 시작 전으로 돌아가야 합니다.
이때 작업 시작 전으로 돌아가는 것을 rollback이라고 합니다.
Atomicity 보장
그럼 이 원자성을 어떻게 보장할 수 있을까요?
원자성을 보장하기 위해서는, 처리 중인 트랜잭션에서 오류가 발생했을 때 현재의 처리 중인 내용을 취소하고,
트랜잭션 실행 시 임시 영역에 저장해두었던 이전의 상태를 다시 불러와서 Rollback 하는 방법이 있습니다.
이때 이전 data를 임시로 저장하는 별도의 영역을 Rollback Segment라고 합니다.
만약 트랜잭션이 처리해야 할 양이 많아지는 경우에는 중간 부분에 Save point를 지정하여 해당 부분 부터만 Rollback 작업을 수행함으로써
리소스의 낭비를 방지하고 처리 시간을 단축할 수 있습니다.
Consistency(일관성)
일관성은 DB의 상태가 일관되어야 한다는 성질입니다.
트랜잭션이 일어난 이후의 DB는 전과 같이 DB의 제약이나 규칙을 만족해야 합니다.
예를 들어 모든 고객은 반드시 이름을 가지고 있어야 한다는 제약이 있다고 가정해봅시다.
다음과 같은 트랜잭션은 Consistency(일관성)을 위반합니다.
1. 이름 없는 새로운 고객을 추가하는 쿼리
2. 기존 고객의 이름을 삭제하는 쿼리
위 예시는 이름이 있어야 한다는 제약을 위반했습니다.
이런 일관되지 않는 상황을 가지면 안됩니다.
마찬가지로 PK, FK 같은 명시적인 무결성 제약 조건을 만족해야 하고, 두 계좌 잔고의 합은 전후가 같아야 한다는 비명시적인 일관성 조건들도 만족해야 합니다.
Consistency 보장
트랜잭션이 일어났을 때 미리 정의된 Trigger를 통해 일관성이 보장될 수 있습니다.
예를 들어, 한 쪽 테이블에 정보의 수정이 일어났을 경우 다른 쪽 테이블에도 함꼐 수정될 수 있도록 명시적으로 자동 업데이트를 하는 명령을 구성하는 방법이 있습니다.
Isolation(격리성, 고립성)
isolation은 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 뜻입니다.
트랜잭션이 수행 되고 있을 때, 다른 트랜잭션의 연산 작업이 중간에 끼어들어 기존 트랜잭션 작업에 영향을 주지 못하도록 독립성을 보장하는 것을 의미합니다.
DB의 트랜잭션도 CPU의 프로세스들과 마찬가지로, 성능과 효율을 위해 병행처리를 할 수 있습니다.
그래서 동시성 제어가 필요하죠.
예를 들어 계좌에 12000원이 있다고 해봅시다.
이 계좌로부터 B 계좌로 6000원, C 계좌로 6000원을 동시에 이체하는 경우, 계좌 B에 먼저 송금한 뒤 계좌 C에 보내는 결과와 동일해야 합니다.
즉, 0원이 되어야 한다는 것이죠, 그런데 동시성 제어가 되지 않으면 6000원이 남을 수도 있습니다.
Isolation 보장
대부분의 DBMS는 다중사용자 DBMS이고, multi-programming 방식이기 때문에 한 트랜잭션을 실행하는 중에 다른 트랜잭션이 끼어들어 실행할 수 있습니다.
이때 동시에 실행되는 트랜잭션들이 서로 간에 간섭함으로써
- lost update(갱신 분실),
- cascading rollback(연쇄 복귀)
- unrecoverability(회복불가능)
- inconsistent analysis(불일치 분석)
등과 같은 문제들이 발생할 수 있습니다.
lost update
트랜잭션들이 동일한 데이터를 동시에 갱신하는 경우에 발생합니다.
또는 이전 트랜잭션이 데이터를 갱신한 후 트랜잭션이 종료되기 전에 나중 트랜잭션이 동일한 데이터를 갱신하여 갱신 값을 덮어쓰는 경우에 발생하는 문제입니다.
Cascading rollback
여러 개의 트랜잭션이 데이터를 공유할 때,
특정 트랜잭션이 이전 상태로 복귀(rollback)할 경우 아무 문제 없는 다른 트랜잭션까지 연달아 복귀하게 되는 문제입니다.
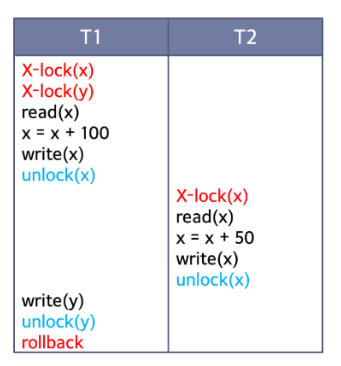
위 그림은 T1 y에 대해 문제가 생겼는데, x에 대해 무사히 작업을 완료한 T1까지 rollback되는 현상입니다.(이전에 T1에 의해 x가 수정되었으니까 T2까지 rollback시켜버립니다.)
Unrecoverability
cascading rollback이 발생했을 때, 그냥 모든 트랜잭션이 다같이 rollback하면 되는데,
이미 한 트랜잭션이 완료된 상태라면, durability에 의해 rollback이 안되는 경우를 말합니다.
Inconsistent analysis
여러 개의 트랜잭션이 동시에 실행할 때 끼어들기로 인해 트랜잭션의 일관성이 유지되지 못하는 상황을 말합니다.
예를 들어 트랜잭션 A가 데이터 X를 읽었을 때 20이었습니다.
A의 트랜잭션이 끝나기 전 트랜잭션 B가 데이터 X를 10으로 바뀌었습니다.
A가 같은 트랜잭션에서 X를 다시 읽으면 10을 읽는, 한 트랜잭션에서 같은 데이터가 바뀌는 경우를 말합니다.
그래서 DB에서 동시성 제어를 해야 합니다.
- Lock & Unlock
데이터를 읽거나 쓰기 작업 중에는 해당 영역에 Lock을 걸어서 다른 트랜잭션이 접근하지 못하도록 하고,
먼저 들어온 트랜잭션 요청이 끝나면 Unlock하여 다른 트랜잭션이 처리될 수 있도록 허용하는 방식을 통해 isolation을 보장할 수 있습니다.
그런데 Lock과 Unlock을 잘못 사용하게 되는 경우 Deadlock에 빠질 수 있습니다.
Lock의 종류
- Shared Lock(공유 Lock, S-lock)
Shared Lock은 데이터를 읽을 때 사용되어지는 Lock입니다. 공유 Lock 끼리는 동시에 접근이 가능합니다.
즉, 하나의 데이터를 읽는 것은 여러 사용자가 동시에 할 수 있다는 것입니다.
하지만 공유 Lock이 설정된 data에 베타(exclusive) Lock을 사용할 수는 없습니다.
데이터를 read한 다음에 unlock합니다.
- Exclusive Lock(베타 Lock, X-lock)
Exclusive Lock은 데이터를 변경할 때 사용되며, 트랜잭션이 완료될 때까지 유지됩니다.
만일 트랜잭션 완료 전에 unlock하게 되면 cascading rollback 문제가 발생할 수도 있습니다.
(사실 예전에는 X-lock을 그냥 데이터 수정 후에 바로 unlock하는 방식도 있었다고 하는데 요즘에는 대부분 트랜잭션 완료 때까지 unlock하지 않습니다.)
exclusive Lock은 해제될 때까지 다른 트랜잭션(Read 작업도 포함)은 해당 리소스에 접근할 수 없습니다.
또한 해당 Lock은 다른 트랜잭션이 수행되고 있는 데이터에 대해서는 접근하여 함께 Lock을 설정할 수 없습니다.
당연하죠, Shared Lock도 Exclusive Lock도 통과시켜주지 않을 테니까요.
Lock 설정 범위(Level)
- DB
DB 전체를 기준으로 lock을 거는 것입니다.
즉, 1개의 세션만이 DB 데이터에 접근 가능합니다.
일반적으로 사용하지 않습니다.
사용하는 경우가 있다면 DB의 소프트웨어 버전을 올린다던지, DB를 복구한다던지 하는 주요한 DB 전체에 대한 업데이트에 사용합니다.
- FILE
DB 파일을 기준으로 lock을 설정합니다.
파일이란 테이블, row 등과 같은 실제 데이터가 쓰여지는 물맂거인 저장소입니다.
해당 범위의 lock은 잘 사용되지 않습니다.
- Table
Table 기준으로 lock을 설정합니다. Index에도 lock을 설정합니다.
이는 테이블의 모든 행을 업데이트 하는 등 전체 테이블에 영향을 주는 변경을 수행할 때 유용합니다.
즉, DDL(Data Definition Language, create, alter, drop 등의 SQL 구문이 포함됨) 구문과 함께 사용되며, DDL Lock이라고도 합니다.
- Page & Block
파일의 일부인 페이지와 블록을 기준으로 Lock을 설정합니다.
잘 사용되지는 않는다고 합니다.
- Column
Column을 기준으로 Lock을 설정합니다.
하지만 이 형식은 lock 설정 및 해제의 리소스가 많이 들기 때문에 일반적으로 잘 사용되지 않습니다. 지원하는 DBMS도 많지 않습니다.
- Row
Row 수준의 lock은 1개의 행을 기준으로 lock을 설정합니다.
DML에 대한 lock으로 가장 일반적으로 사용하는 lock입니다.
Escalation
Lock 리소스가 임계치를 넘으면 lock 레벨이 확장되는 것을 의미합니다.
Lock 레벨이 낮을 수록 동시성이 좋아지지만, 관리해야할 lock이 많아지기 때문에 메모리 효율성은 떨어집니다.
반대로 Lock 레벨이 높을 수록 관리 리소느는 낮지만, 동시성은 떨어집니다.
다음과 같이 두 가지 Lock 방식이 있습니다.
- Conservative Locking(보수적 locking)
트랜잭션이 시작되면 모두 Lock을 걸어버리는 방식으로 데드락이 발생하는 경우는 없으나 병행성이 떨어지게 됩니다.
- Strict Locking(강한 locking)
트랜잭션이 완전히 Commit 될 때까지 Lock을 걸어두고 있다가 Commit 이후 Unlock을 하는 방식으로 데드락이 발생할 수 있지만 병행성이 좋습니다.
2PL protocol(2-Phase Locking protocol)
데이터 오류 가능성을 사전에 예방하는 직렬 가능한 스케줄을 보장하는 방법 중 하나입니다.
잠금을 설정하는 단계와 해제하는 단계로 나누어 수행합니다.
- Growing phase(확장단계) : 트랜잭션이 lock 연산만 수행할 수 있고, unlock은 수행할 수 없는 단계
- Shrinking phase(축소단계) : 트랜잯녀이 unlock 연산만 수행할 수 있고, lock 연산은 수행할 수 없는 단계
2PL은 cascading rollback 문제도 발생할 수 있습니다.
이는 x-lock을 트랜잭션이 끝나기 전에 unlock해서 생기는 문제입니다.
요즘은 x-lock을 트랜잭션이 끝나고 나서 unlock하는 strict 2PL을 써서 cascading rollback 문제를 해결합니다.
x-lock을 트랜잭션이 끝나고 unlock하게 되면 commit되지 않은 트랜잭션에 의해 변경된 data를
다른 트랜잭션이 읽거나 쓸 가능성을 원천적으로 차단하기 때문에 cascading rollback 문제가 해결됩니다.
deadlock 문제가 해결되지 않는다는 단점이 있습니다.
deadlock에 대해서는 뒤에서 또 다루겠습니다.
Blocking
Blocking은 lock 간 경합이 발생하여 특정 transaction이 작업을 진행하지 못하고 멈춰선 상태를 말합니다.
위에서 설명했듯이 shared lock끼리는 블로킹이 발생하지 않지만 exclusive lock은 blocking을 발생시킵니다.
blocking을 해소하기 위해서는 이전 트랜잭션이 완료(commit 또는 rollback)되어야 합니다.
뒤에 들어온 트랜잭션은 이전 트랜잭션이 마무리되어야 진행이 가능하죠.. Lock 때문에요.
blocking을 성능에 좋지 않고, 그래서 최대한 경합을 최소화 해야 합니다.
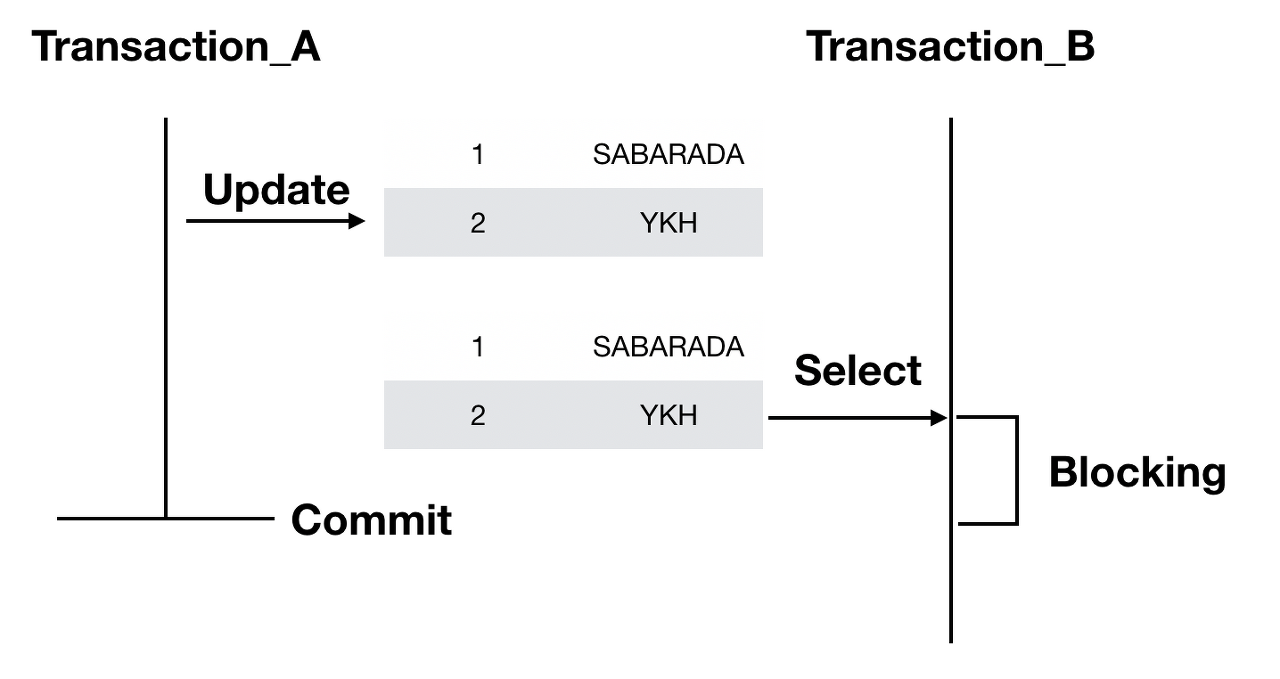
위 그림을 보면 트랜잭션 A가 update를 실행하려고 exclusive lock을 걸어버려서
트랜잭션 B가 data에 접근하지 못하고 트랜잭션 A가 commit될 때까지 blocking 되었습니다.
다음은 blocking 방지를 위한 몇가지 주의사항입니다.
1. 한 트랜잭션의 길이를 너무 길게하는 것은 blocking의 확률을 올립니다.
즉, 작업 단위를 쪼개는 것이 방법이 될 수 있습니다.
2. 같은 데이터를 갱신하는 트랜잭션이 동시에 수행되지 않도록 해야 합니다.
3. 트랜잭션 격리성 수준을 불필요하게 상향 조정하지 않습니다.(isolation level에서 자세히 다룹시다.)
4. 쿼리를 오랜시간 잡아두지 않도록 적절한 튜닝을 진행합니다.
SQL 문이 복잡하면 리팩토링을 통해 빠르게 실행되도록 합니다.
(lock timeout 설정으로 lock의 최대 시간을 지정해주는 방법도 있습니다.)
Deadlock
DB에서의 deadlock은 두 트랜잭션이 각각 lock을 설정한 후 서로의 lock에 접근하여 값을 얻어오려고 할 때,
서로의 lock에 막혀 양쪽 트랜잭션 모두 영원히 처리되지 않는 상태를 말합니다.
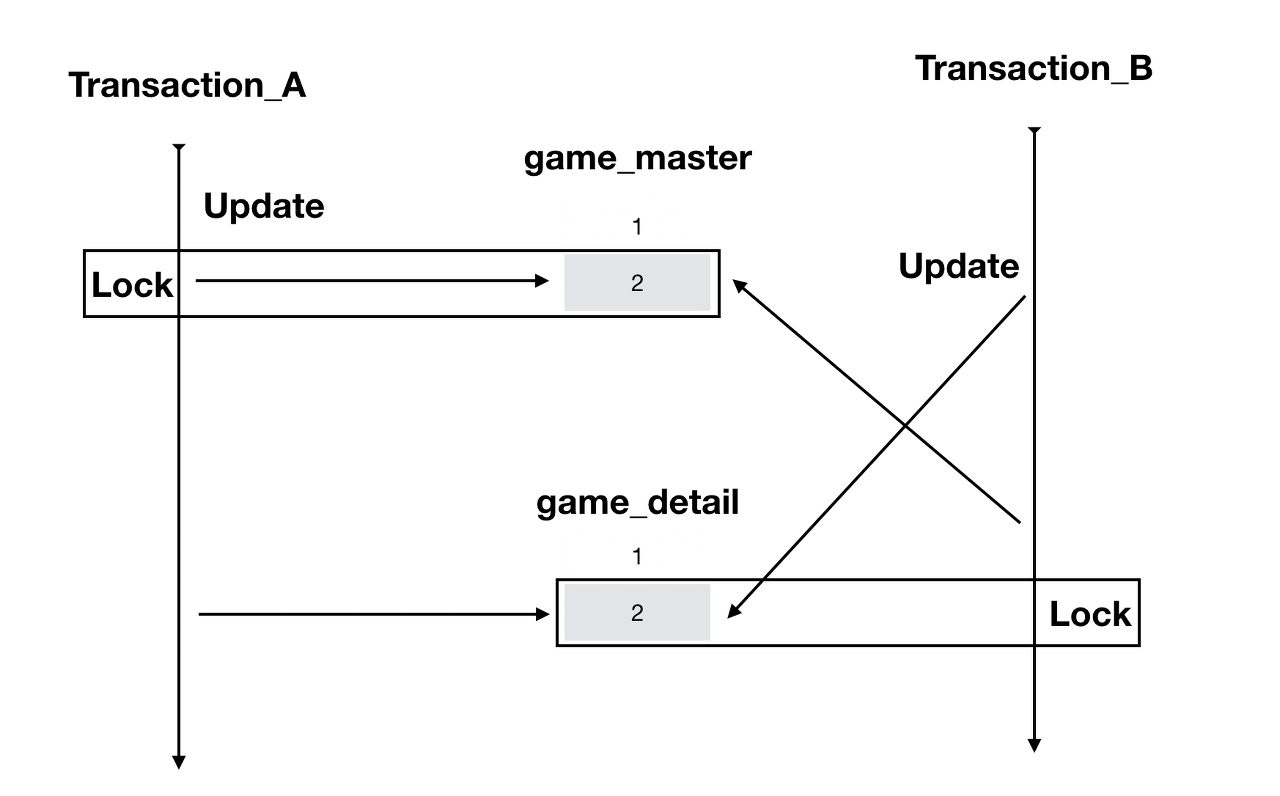
위 예시에서는 트랜잭션 A가 game_master 테이블 2번 row에 lock 걸었습니다.
트랜잭션 B는 game_detail 테이블 2번 row에 lock을 걸었죠.
그 후에 트랜잭션 A는 B가 lock을 건 game_detail 2번 row에 접근하려 하고,
트랜잭션 B는 A가 lock을 건 game_master 2번 row에 접근하려 합니다.
이 경우 영원이 서로의 lock이 풀리게 되길 기다리면서 deadlock이 발생합니다.
이렇게 교착상태가 발생하게 되면 DBMS가 둘 중 한 트랜잭션에 에러를 발생시킴으로써(트랜잭션을 취소시킴으로써) 문제를 해결합니다.
어떤 트랜잭션이 취소될 지는 판단하기 어렵습니다.
데드락 방지 기법
- 접근 순서 규칙 정하기
Deadlock 방지를 위해 접근 순서를 동일하게 하는 것이 중요합니다.
위 예시에서 만일 트랜잭션 B가 game_master 테이블 2번 row에 먼저 접근했다면
blocking이 생길지언정 deadlock은 발생하지 않습니다.
트랜잭션 B가 game_master 2번 row에서 blocking 되어서 game_detail 2번 row에는 락이 걸려있지 않으니
트랜잭션 A가 commit 되고 game_master 2번 row가 unlock될 것이고, 트랜잭션 B가 실행가능해질 것입니다.
- MVCC(Multi-Version Concurrency Control, 다중 버전 동시성 제어)
MVCC 모델에서는 다음과 같은 Snapshot을 이용하는 방법으로 동시성을 제어하여 데드락을 방지하고 개선된 트랜잭션 성능을 보장합니다.
1. 트랜잭션이 일어나는 특정 시점의 DB Snapshot을 읽습니다.
2. 이 Snapshot 데이터에 대한 트랜잭션 수행 중 발생하는 변경 사항은 다른 사용자가 볼 수 없습니다.(트랜잭션이 Commit 될 때까지)
3. 데이터가 업데이트 되면, 이전의 데이터를 덮어쓰는 것이 아니고 새로운 버전의 데이터를 만듭니다.
4. 대신 이전 버전의 데이터와 비교해서 변경된 내용을 기록합니다.
5. 위와 같은 과정에 의해 하나의 데이터에 대해 여러 버전의 데이터가 존재하게 됩니다.
6. 사용자는 가장 마지막 버전의 데이터를 읽게 됩니다.
MVCC 접근 방식은 Snapshot을 이용하여 Locking을 필요로 하지 않기 때문에 일반적인 RDBMS보다 더 빠르게 동작한다고 합니다.
또한 데이터를 읽기 시작할 때, 다른 사람이 그 데이터를 삭제하거나 수정하더라도 영향을 받지 않고 데이터를 사용할 수 있습니다.
단, MVCC 방식을 사용하게 될 경우 사용하지 않는 데이터가 쌓이게 되므로 데이터를 적절히 정리해주는 별도의 시스템이 필요합니다.
또한 데이터의 버전이 충돌하면 application 영역에서 이를 해결해줘야 합니다.
그런데 ACID 원칙을 strict하게 지키면 동시성이 매우 떨어지기 때문에 DB 엔진은 ACID 원칙을 희생하고 동시성을 얻을 수 있는 방법을 제공합니다.
그게 바로 isolation level입니다.
isolation 원칙을 덜 지키는 level을 사용할 수록 문제가 발생할 가능성은 커지지만 동시에 더 높은 동시성을 얻을 수 있습니다.
이 부분은 범위를 넘어서니 다음에 작성할 사람에게 맡기겠습니다.
Durability(지속성)
트랜잭션이 성공적으로 완료되면 그 트랜잭션이 갱신한 DB 내용은 영구적으로 저장되어야 한다는 조건입니다.
Recovery
recovery는 트랜잭션을 수행하는 도중 장애가 발생했을 때 손상 이전 상태로 복구하는 작업입니다.
장애의 유형
- 트랜잭션 장애: 입력 data 오류, 불명확한 데이터, 시스템 자원 요구의 과다 등 트랜잭션 내부의 비정상적인 상황으로 인하여 프로그램 실행이 중지되는 현상
- 시스템 장애: DB에 선상을 입히지 않으나 하드웨어 오동작, 소프트웨어 손상, deadlock 등에 의해 모든 트랜잭션의 연속적인 수행에 장애를 주는 현상
- 미디어 장애: 저장장치인 디스크 블록의 손상이나 디스크 헤드의 충돌 등에 의해 DB의 일부 또는 전부가 물리적으로 손상된 상태
Recovery Management(회복 관리기)
- Recovery management는 DBMS의 구성 요소입니다.
- 트랜잭션 실행이 성공적으로 완료되지 못하면 트랜잭션이 DB에 생성했떤 모든 변화를 Undo 시키고, 트랜잭션 수행 이전의 원래 상태로 복구하는 역할을 담당합니다.
- memory dump, log 등을 이용하여 회복을 수행합니다.
Undo(취소)
log에 보관한 정보를 이용하여 가장 최근에 변경된 내용부터 거슬러 올라가면서 작업을 취소하여 원래의 DB로 복구합니다.
Dump
DB 전체를 복사해 두는 것입니다.
Log
갱신되기 전후의 내용을 기록하는 별도의 파일로, Journal이라고도 합니다.
Redo
덤프와 로그를 이용하여 가장 최근의 정상적인 DB로 회복시킨 후 트랜잭션을 재실행 시킵니다.
회복 기법
Deferred Update(연기 갱신 기법)
트랜잭션이 성공적으로 완료될 때까지 DB에 대한 실질적인 갱신을 연기하는 기법입니다.
- 트랜잭션이 수행되는 동안 내용은 일단 Log에 보관합니다.
- 트랜잭션의 부분 완료 시점에 Log에 보관한 갱신 내용을 실제 DB에 기록합니다.
- 트랜잭션이 부분 완료되기 전에 장애가 발생하여 트랜잭션이 rollback되면,
어차피 실제 DB에 영향을 미치지 않았기 때문에 어떠한 갱신 내용도 undo 시킬 필요 없이 무시하면 됩니다.
- Redo 작업만 가능합니다.
Immediate Update(즉각 갱신 기법)
트랜잭션이 data를 갱신하면 트랜잭션이 부분 완료 전이라도 즉시 실제 DB에 반영하는 방법입니다.
- 장애가 발생하여 회복 작업할 경우를 대비하여 갱신된 내용들은 log에 보관합니다.
- Undo, Redo 모두 사용 가능합니다.
Shadow Paging(그림자 페이지 대체 기법)
갱신 이전의 DB를 일정 크기의 page 단위로 구성하여 각 page마다 복사본인 shadow page로 별도 보관해놓고,
실제 page를 대상으로 트랜잭션에 의한 갱신 작업을 하다가, 장애가 발생하여 트랜잭션 작업을 rollback시킬 때,
갱신된 이후의 실제 page 부분에 shadow page를 대체하여 회복시키는 기법입니다.
- Log, Undo, Redo 알고리즘이 필요없습니다.
Check point(검사점 기법)
트랜잭션 실행 중 특정 단계에서 재실행할 수 있도록 갱신 내용이나 시스템에 대한 상황 등에 관한 정보와 함께 check point를 로그에 보관해두고,
장애 발생 시 트랜잭션 전체를 rollback하지 않고 check point부터 회복 작업을 하여 회복시간을 줄이도록 하는 기법입니다.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
555
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
-1 OR 2+209-209-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:40 p.m.
-1 OR 2+194-194-1=0+0+0+1
Updated: Feb. 22, 2025, 5:40 p.m.
-1' OR 2+472-472-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:40 p.m.
-1' OR 2+552-552-1=0+0+0+1 or 'TPQ8myqP'='
Updated: Feb. 22, 2025, 5:40 p.m.
-1" OR 2+580-580-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:40 p.m.
1*if(now()=sysdate(),sleep(15),0)
Updated: Feb. 22, 2025, 5:40 p.m.
10'XOR(1*if(now()=sysdate(),sleep(15),0))XOR'Z
Updated: Feb. 22, 2025, 5:40 p.m.
10"XOR(1*if(now()=sysdate(),sleep(15),0))XOR"Z
Updated: Feb. 22, 2025, 5:40 p.m.
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Updated: Feb. 22, 2025, 5:40 p.m.
1-1; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:40 p.m.
1-1); waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:40 p.m.
1-1 waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:40 p.m.
1Tf9Xka9T'; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:40 p.m.
1-1 OR 28=(SELECT 28 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
1-1) OR 680=(SELECT 680 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
1-1)) OR 26=(SELECT 26 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
1qp7ZLdGl' OR 842=(SELECT 842 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
18DWNo6b2') OR 104=(SELECT 104 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
1bktFBplv')) OR 700=(SELECT 700 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:40 p.m.
1*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Updated: Feb. 22, 2025, 5:40 p.m.
1'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Updated: Feb. 22, 2025, 5:40 p.m.
1
Updated: Feb. 22, 2025, 5:40 p.m.
1'"
Updated: Feb. 22, 2025, 5:40 p.m.
1����%2527%2522\'\"
Updated: Feb. 22, 2025, 5:40 p.m.
@@PAjZY
Updated: Feb. 22, 2025, 5:40 p.m.
555
Updated: Feb. 22, 2025, 5:40 p.m.
555
Updated: Feb. 22, 2025, 5:40 p.m.
555
Updated: Feb. 22, 2025, 5:40 p.m.